Tutorial 1: Descripción de variables por grupos
Presentación: el problema de resumir por grupos.
Mientras realizamos la exploración de un conjunto de datos suele ser frecuente que queramos calcular medidas descriptivas (medias, desviaciones típicas, etc) por grupos. Por ejemplo, en nuestro estudio de los hábitos de nidificación de las tortugas de Cabo Verde, tras leer los datos:
podemos comprobar que nuestra base de datos contiene las siguientes variables:
| Año | periodo | LCC | ACC | peso | Huevos | playa | distancia | profNido | crias_Emerg | crias_Muertas | hrotos | cangrejos |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2002 | 1 | 74.8 | 77.2 | 51.5 | 70 | Ponta Cosme | 30.6 | 52.6 | 24 | 0 | 46 | 1 |
| 2002 | 1 | 81.4 | 73.6 | 59.3 | 86 | Calheta | 22.4 | 35.4 | 65 | 3 | 18 | 0 |
| 2002 | 3 | 87.9 | 76.1 | 65.7 | 109 | Ponta Cosme | 24.1 | 43.3 | 0 | 2 | 107 | 1 |
| 2003 | 2 | 73.8 | 68.7 | 58.6 | 95 | Porto Ferreiro | 31.1 | 57.5 | 58 | 0 | 37 | 0 |
| 2004 | 1 | 75.9 | 72.9 | 55.2 | 83 | Calheta | 18.9 | 36.2 | 77 | 1 | 5 | 1 |
| 2004 | 3 | 82.9 | 75.9 | 50.1 | 85 | Ponta Cosme | 30.1 | 40.7 | 2 | 0 | 83 | 1 |
Supongamos que quisiéramos calcular la profundidad media de los nidos según la playa en que se encuentren, o el total de huevos por playa. Podemos llevar a cabo este cálculo de diversas maneras. En este pequeño tutorial explicaremos como hacerlo de dos formas:
A través de la función
aggregate(función del paquete base de R).A través de las funciones de la librería
dplyr.
Debemos señalar, en cualquier caso, que las funciones de dplyr resultan mucho más cómodas y eficientes para realizar estas tareas y constituyen la opción actualmente más recomendable. Quien lo desee puede saltarse la sección del aggregate e ir directamente a la sección del dplyr
Resumenes por grupos mediante la función aggregate.
Para usar esta función indicamos en primer lugar la variable que queremos resumir (profNido), seguida del símbolo “~”, y de la variable de agrupación (playa). Con ello indicamos que queremos resumir la primera variable para cada valor de la segunda; a continuación especificamos el nombre del data.frame que contiene los datos (en este caso, tortugas), la función a aplicar (en este caso la media mean), y las opciones que queramos añadir a esta función (utilizaremos na.rm=TRUE para evitar que los valores perdidos interfieran con el cálculo):
El resultado (medias) es un data.frame cuyo contenido podemos mostrar de manera “elegante” mediante:
| playa | profNido |
|---|---|
| Calheta | 35.309 |
| Ervatao | 58.433 |
| Ponta Cosme | 44.566 |
| Porto Ferreiro | 42.639 |
Para calcular el total de huevos en cada playa, usamos la función sum dentro de aggregate:
totalHuevos <- aggregate(Huevos~playa, tortugas, sum, na.rm=TRUE)
kable(totalHuevos) %>%
kable_styling(full_width = FALSE)| playa | Huevos |
|---|---|
| Calheta | 2947 |
| Ervatao | 7653 |
| Ponta Cosme | 7568 |
| Porto Ferreiro | 2639 |
La función aggregate permite agrupar por más de una variable. Si, por ejemplo, quisiéramos calcular la profundidad media de los nidos por playa según periodos de muestreo, utilizaríamos la siguiente sintaxis:
medias <- aggregate(profNido~playa + periodo, tortugas, mean, na.rm=TRUE)
kable(medias) %>%
kable_styling(full_width = FALSE)| playa | periodo | profNido |
|---|---|---|
| Calheta | 1 | 35.757 |
| Ervatao | 1 | 59.572 |
| Ponta Cosme | 1 | 45.958 |
| Porto Ferreiro | 1 | 39.560 |
| Calheta | 2 | 34.480 |
| Ervatao | 2 | 58.117 |
| Ponta Cosme | 2 | 45.777 |
| Porto Ferreiro | 2 | 44.188 |
| Calheta | 3 | 34.638 |
| Ervatao | 3 | 59.562 |
| Ponta Cosme | 3 | 44.737 |
| Porto Ferreiro | 3 | 46.837 |
| Calheta | 4 | 36.112 |
| Ervatao | 4 | 57.735 |
| Ponta Cosme | 4 | 44.450 |
| Porto Ferreiro | 4 | 39.025 |
| Calheta | 5 | 35.300 |
| Ervatao | 5 | 57.629 |
| Ponta Cosme | 5 | 43.068 |
| Porto Ferreiro | 5 | 40.625 |
Si queremos aplicar varias funciones en cada grupo de datos, debemos construir primero una función que “contenga” todas las funciones que queremos aplicar. Por ejemplo, si para cada playa queremos calcular el valor medio y la desviación típica de la profundidad de los nidos, construimos primero una función que calcule estas dos cantidades:
y a continuación la utilizamos como argumento de aggregate:
## playa profNido.media profNido.sd
## 1 Calheta 35.3086 4.7130
## 2 Ervatao 58.4326 5.4051
## 3 Ponta Cosme 44.5656 6.1534
## 4 Porto Ferreiro 42.6394 6.3197Merece la pena observar la estructura del objeto que hemos construido:
## 'data.frame': 4 obs. of 2 variables:
## $ playa : chr "Calheta" "Ervatao" "Ponta Cosme" "Porto Ferreiro"
## $ profNido: num [1:4, 1:2] 35.31 58.43 44.57 42.64 4.71 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr "media" "sd"Como vemos, es un data.frame que contiene 2 variables a pesar de que parece que contiene 3; en realidad los valores de media y sd forman en realidad una matriz, de nombre profNido. Esto impide que podamos utilizar kable, ya que esta función espera un data.frame “puro”. Si usamos kable directamente se produce un error:
## Error in dimnames(x) <- dn: la longitud de 'dimnames' [2] no es igual a la extensión del arregloPara evitar este comportamiento debemos convertir profPlaya en un verdadero data.fame. Ello se consigue mediante:
Como vemos ahora sí que tenemos un data.frame con tres columnas:
## 'data.frame': 4 obs. of 3 variables:
## $ playa: Factor w/ 4 levels "Calheta","Ervatao",..: 1 2 3 4
## $ media: num 35.3 58.4 44.6 42.6
## $ sd : num 4.71 5.41 6.15 6.32Ahora podemos usar kable sin problemas para presentar la tabla:
| playa | media | sd |
|---|---|---|
| Calheta | 35.309 | 4.7130 |
| Ervatao | 58.433 | 5.4051 |
| Ponta Cosme | 44.566 | 6.1534 |
| Porto Ferreiro | 42.639 | 6.3197 |
Obviamente todo esto parece complicadísimo ¿Por qué la salida de aggregate en unos casos se puede pasar directamente a kable y en otros casos no? ¿Por qué aggregate genera una estructura tan “extraña” con dos elementos, uno de los cuales es una columna con los nombres de las playas y otro es una matriz con dos variables? En realidad la explicación de este comportamiento procede simplemente de que R es un compendio de librerías y funciones construidas por muchos autores que en su diseño no pensaron que la salida de su función pudiera ser usada como entrada de otra función, dando lugar a esta suerte de incompatibilidad que requiere un esfuerzo adicional de ajuste por parte del usuario.
Resúmenes por grupos utilizando el paquete dplyr
El paquete dplyr integra numerosas funciones para resumir y describir datos, que son totalmente compatibles unas con otras y que presentan salidas más refinadas y generales que aggregate.
En primer lugar cargamos esta librería:
Para obtener resúmenes por grupo utilizaremos la función group_by(); y para especificar qué función de resumen queremos emplear utilizamos summarize(). Así, para obtener la profundidad media de los nidos por playa, la sintaxis a emplear es:
tortugas %>%
group_by(playa) %>%
summarize(media=mean(profNido,na.rm=TRUE)) %>%
kable %>%
kable_styling(full_width = FALSE)| playa | media |
|---|---|
| Calheta | 35.309 |
| Ervatao | 58.433 |
| Ponta Cosme | 44.566 |
| Porto Ferreiro | 42.639 |
Aquí el operador tubería ( %>% ) hace que la salida de cada comando sea directamente la entrada del siguiente; por ello en kable ni siquiera hemos especificado qué objeto queremos mostrar; se entiende que es el que viene directamente de la tubería anterior.
Si queremos especificar varias funciones no es necesario definir previamente una única función combinada; basta con especificar las funciones a aplicar dentro del summarize:
tortugas %>%
group_by(playa) %>%
summarize(media=mean(profNido,na.rm=TRUE),
sd=sd(profNido,na.rm=TRUE),
mediana=median(profNido,na.rm=TRUE)) %>%
kable %>%
kable_styling(full_width = FALSE)| playa | media | sd | mediana |
|---|---|---|---|
| Calheta | 35.309 | 4.7130 | 36.00 |
| Ervatao | 58.433 | 5.4051 | 58.30 |
| Ponta Cosme | 44.566 | 6.1534 | 44.95 |
| Porto Ferreiro | 42.639 | 6.3197 | 42.00 |
Para obtener el número total y el número medio de huevos por nido en playa:
tortugas %>%
group_by(playa) %>%
summarize(total=sum(Huevos,na.rm=TRUE),
numero_Medio=mean(Huevos,na.rm=TRUE)) %>%
kable %>%
kable_styling(full_width = FALSE)| playa | total | numero_Medio |
|---|---|---|
| Calheta | 2947 | 84.200 |
| Ervatao | 7653 | 83.185 |
| Ponta Cosme | 7568 | 84.089 |
| Porto Ferreiro | 2639 | 79.970 |
Con dplyr es fácil también obtener resúmenes agrupando por varias variables; por ejemplo, para describir la profundidad de los nidos durante cada periodo dentro de cada playa:
tortugas %>%
group_by(periodo,playa) %>%
summarize(media=mean(profNido,na.rm=TRUE),
sd=sd(profNido,na.rm=TRUE),
mediana=median(profNido,na.rm=TRUE)) %>%
kable %>%
kable_styling(full_width = FALSE)| periodo | playa | media | sd | mediana |
|---|---|---|---|---|
| 1 | Calheta | 35.757 | 4.2296 | 35.40 |
| 1 | Ervatao | 59.572 | 5.1863 | 59.65 |
| 1 | Ponta Cosme | 45.958 | 7.4685 | 46.65 |
| 1 | Porto Ferreiro | 39.560 | 2.9552 | 38.20 |
| 2 | Calheta | 34.480 | 2.1064 | 35.30 |
| 2 | Ervatao | 58.117 | 5.8537 | 57.75 |
| 2 | Ponta Cosme | 45.777 | 8.1453 | 45.10 |
| 2 | Porto Ferreiro | 44.188 | 7.0369 | 43.00 |
| 3 | Calheta | 34.638 | 5.4324 | 36.00 |
| 3 | Ervatao | 59.562 | 5.4808 | 59.80 |
| 3 | Ponta Cosme | 44.737 | 4.3793 | 44.20 |
| 3 | Porto Ferreiro | 46.837 | 6.2482 | 45.70 |
| 4 | Calheta | 36.112 | 5.0815 | 37.15 |
| 4 | Ervatao | 57.735 | 4.3215 | 58.30 |
| 4 | Ponta Cosme | 44.450 | 5.5049 | 44.80 |
| 4 | Porto Ferreiro | 39.025 | 4.4500 | 40.85 |
| 5 | Calheta | 35.300 | 6.1803 | 36.70 |
| 5 | Ervatao | 57.629 | 6.2994 | 54.70 |
| 5 | Ponta Cosme | 43.068 | 6.2695 | 45.05 |
| 5 | Porto Ferreiro | 40.625 | 6.2278 | 41.90 |
Otra posibilidad que ofrece dplyr es resumir simultáneamente varias variables por grupos. Así, por ejemplo, si queremos calcular los valores medios de LCC, ACC y peso por playa, utilizamos la función summarize_at():
tortugas %>%
group_by(playa) %>%
summarize_at(c("LCC","ACC","peso"), mean, na.rm=TRUE) %>%
kable %>%
kable_styling(full_width = FALSE)| playa | LCC | ACC | peso |
|---|---|---|---|
| Calheta | 82.211 | 76.937 | 59.389 |
| Ervatao | 81.428 | 76.868 | 59.948 |
| Ponta Cosme | 83.377 | 77.876 | 61.817 |
| Porto Ferreiro | 81.727 | 76.900 | 61.061 |
Si para cada variable en cada grupo se desea evaluar varias funciones, éstas deben especificarse como una lista, donde resulta conveniente asignar un nombre distinto al resultado de cada función (en caso contrario, la salida puede resultar confusa):
tortugas %>%
group_by(playa) %>%
summarize_at(c("LCC","ACC","peso"), list(media=mean,sd=sd), na.rm=TRUE) %>%
kable %>%
kable_styling(full_width = FALSE)| playa | LCC_media | ACC_media | peso_media | LCC_sd | ACC_sd | peso_sd |
|---|---|---|---|---|---|---|
| Calheta | 82.211 | 76.937 | 59.389 | 4.7725 | 3.9345 | 5.9592 |
| Ervatao | 81.428 | 76.868 | 59.948 | 4.8110 | 3.9441 | 4.8982 |
| Ponta Cosme | 83.377 | 77.876 | 61.817 | 5.0639 | 4.6604 | 4.9041 |
| Porto Ferreiro | 81.727 | 76.900 | 61.061 | 4.7160 | 4.6925 | 4.0463 |
Gráficos de los resúmenes por grupo
Si hemos utilizado dplyr es muy fácil emplear ggplot para representar gráficamente los valores obtenidos. Si con el resumen por grupos queremos hacer tanto tablas como gráficos es conveniente guardar previamente en un objeto el resultado. Así, por ejemplo, si queremos mostrar el número total de huevos por año realizamos primero el cálculo y lo asignamos al objeto huevosAño:
que en forma de tabla puede presentarse como:
| Año | total |
|---|---|
| 1999 | 3509 |
| 2000 | 3552 |
| 2001 | 3034 |
| 2002 | 3583 |
| 2003 | 2701 |
| 2004 | 4428 |
y gráficamente: (téngase en cuenta que la variable “Año” se ha leido como carácter, por lo que la pasamos a numérica mediante as.numeric())
library(ggplot2)
ggplot(huevosAño, aes(x=as.numeric(Año), y=total)) + geom_point() + geom_line(linetype=2,color="red") +
xlab("Año") + ylab("Número total de huevos")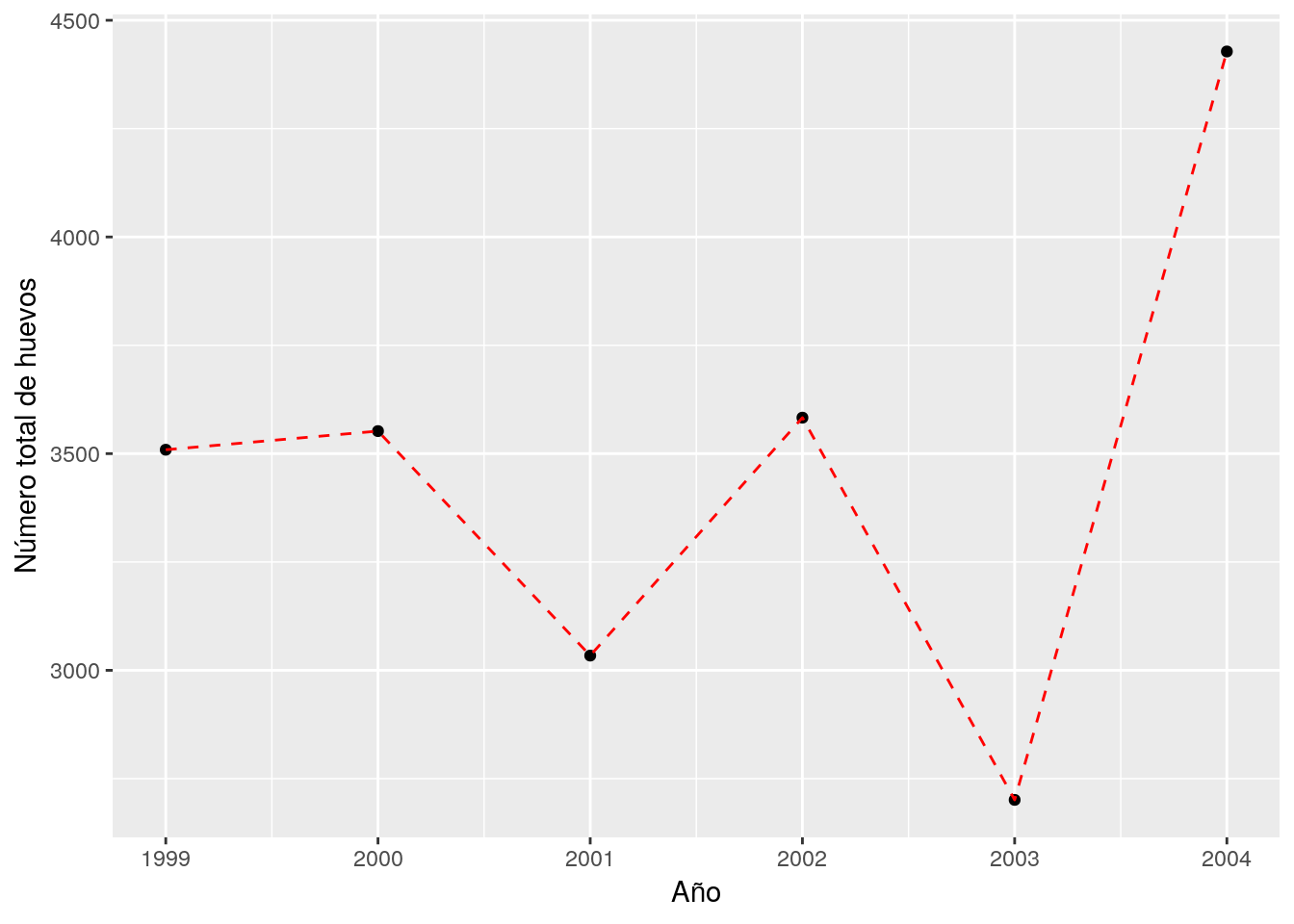
Si sólo queremos el gráfico sin mostrar una tabla, puede generarse directamente el gráfico mediante una tubería ( %>% ) directamente desde los datos:
tortugas %>%
group_by(Año) %>%
summarize(total=sum(Huevos,na.rm=TRUE)) %>%
ggplot(aes(x=as.numeric(Año), y=total)) + geom_point() + geom_line(linetype=2,color="red") +
xlab("Año") + ylab("Número total de huevos")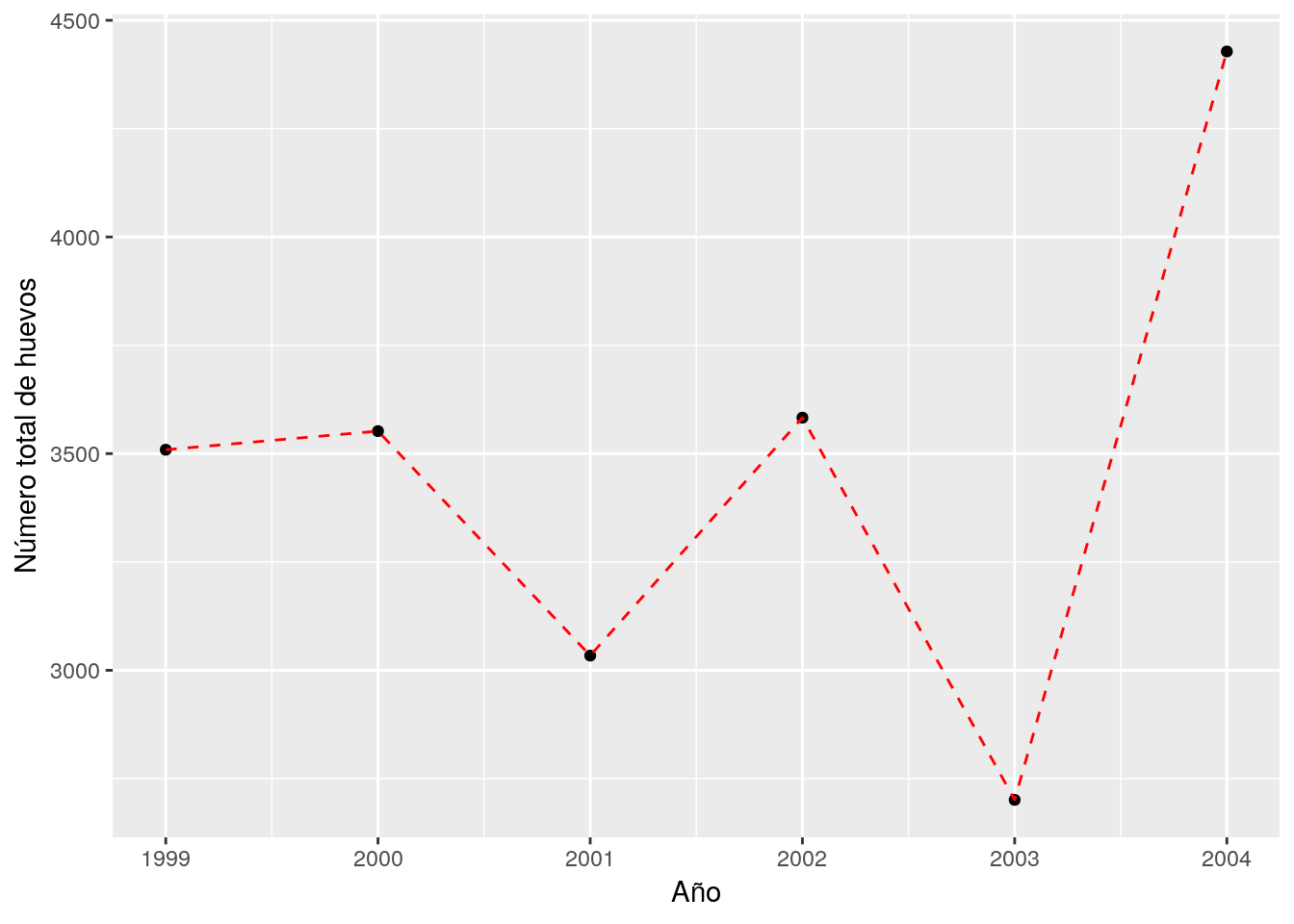
Si realizamos la agrupación según varias variables (año y playa, por ejemplo), tampoco entraña mucha dificultad trazar el gráfico:
tortugas %>%
group_by(Año,playa) %>%
summarize(total=sum(Huevos,na.rm=TRUE)) %>%
ggplot(aes(x=as.numeric(Año), y=total, color=playa)) + geom_point() + geom_line() +
xlab("Año") + ylab("Número total de huevos")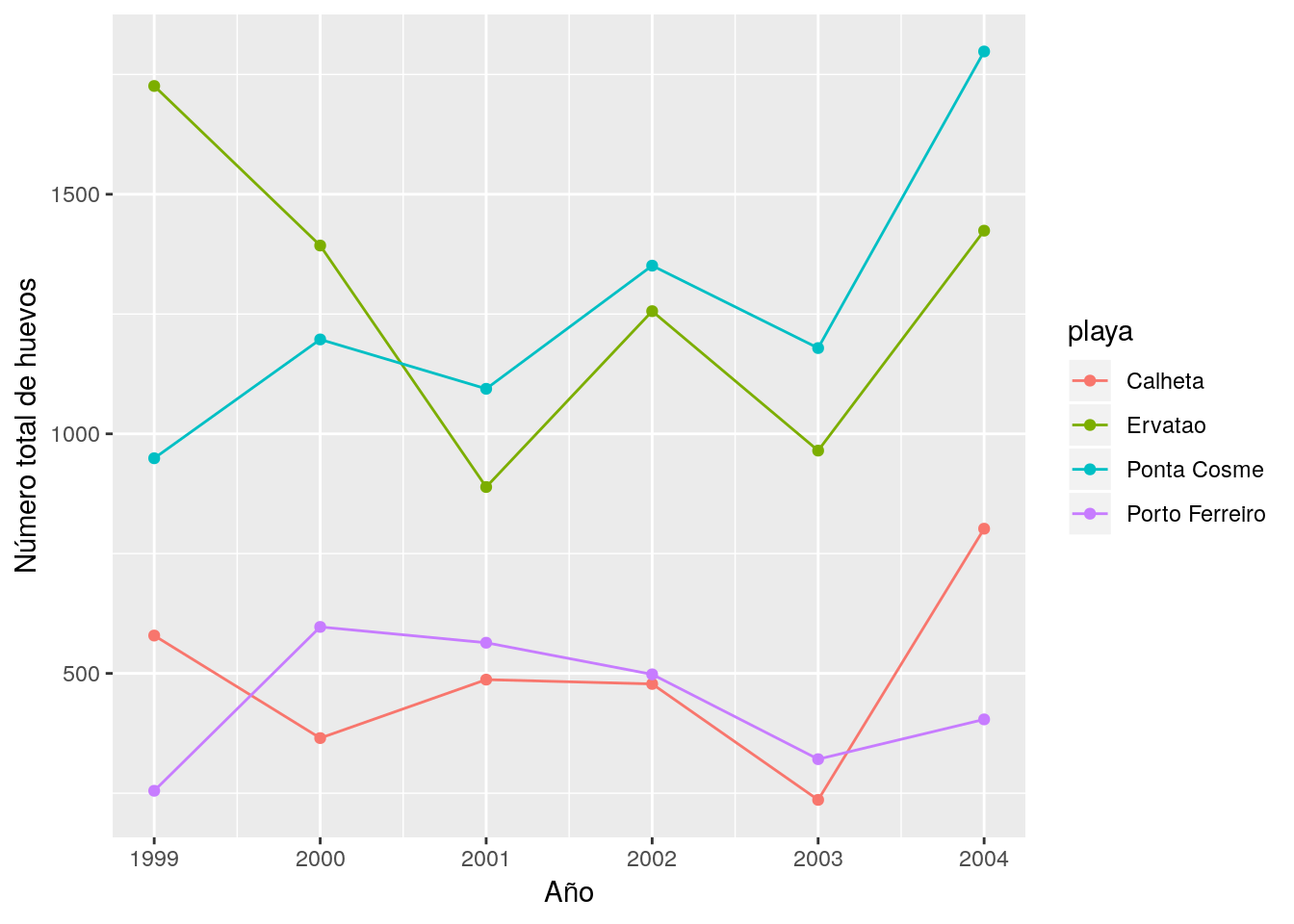
© 2016 Angelo Santana, Carmen N. Hernández, Departamento de Matemáticas ULPGC