Gráficos en R: introducción
Angelo Santana & Carmen Nieves Hernández,
Departamento de Matemáticas, ULPGC
Los gráficos en R
R dispone de múltiples funciones diseñadas para la representación gráfica de datos. Estas funciones se dividen en dos grandes grupos: funciones gráficas de alto nivel y de bajo nivel. La diferencia fundamental es que las funciones de alto nivel son las que generan gráficos completos, mientras que las de bajo nivel se limitan a añadir elementos a un gráfico existente (por tanto creado por una función de alto nivel).
El paquete graphics (que se carga en memoria cada vez que arrancamos R) contiene un buen número de funciones de alto y bajo nivel para generar gráficos. Numerosos paquetes -plotrix, scatterplot3D, rgl, maps, shapes, …, y sobre todo ggplot2- contienen muchísimas más funciones gráficas que mejoran y complementan las que vienen por defecto con R.
Funciones gráficas de alto nivel
Estas funciones son las que generan gráficos completos. Entre las más utilizadas podemos citar plot() (gráficos de nubes de puntos, entre otros), hist() (histogramas), barplot() (diagramas de barras), boxplot() (diagramas de caja y bigote), pie() (diagrama de sectores) o pers() (superficies en 3D). Todas estas funciones disponen de multitud de argumentos que permiten controlar las etiquetas de los ejes, sus límites, títulos, tamaño, colores, etc.:
xlim,ylim: controlan, respectivamente, la extensión de los ejes X e Y. Asíxlim=c(0,10)indica que el eje X se extiende de 0 a 10;ylim=c(-5,5)indica que el eje Y va de -5 a 5. Si no se incluyen estos valores, R los ajusta por defecto de modo que se incluyan todos los valores disponibles en el dataframe.xlabeylabespecifican las etiquetas para los ejes X e Y respectivamente.mainindica el título del gráfico.subpermite especificar un subtítulo.
Los ejemplos que se muestran más abajo permiten ver como utilizar estas opciones.
Dos argumentos importantes que son comunes a la mayoría de gráficos de alto nivel son los siguientes:
add=TRUE: fuerza a la función a actuar como si fuese de bajo nivel (intenta superponer la figura que genera a un gráfico ya existente). Esta opción no está disponible para todas las funciones.typeIndica el tipo de gráfico a realizar. En concreto:type="p"representa puntos (opción por defecto)type="l"representa líneastype="b"(both, ambos) representa puntos unidos por líneas.type="n"No dibuja nada.
Funciones gráficas de bajo nivel:
Permiten añadir líneas, puntos, etiquetas… a un gráfico ya existente. Son de gran utilidad para completar un gráfico. Entre estas funciones cabe destacar:
lines(): Permite añadir lineas (uniendo puntos concretos) a una gráfica ya existente.abline(): Añade lineas horizontales, verticales u oblicuas, indicando pendiente y ordenada.points(): Permite añadir puntos.legend(): Permite añadir una leyenda.text(): Añade texto en las posiciones que se indiquen.grid(): Añade una malla de fondo.title(): permite añadir un título o subtítulo.
Argumentos comunes a las funciones gráficas de alto y bajo nivel
Los siguientes argumentos opcionales son comunes a muchas funciones gráficas de alto y bajo nivel. Sus valores por defecto pueden obtenerse ejecutando la función par(). Se puede encontrar el significado y valores posibles de cada uno de estos argumentos (y muchos más) ejecutando help(par).
pch: Indica la forma en que se dibujaran los puntos (círculo, cuadrado, estrella, etc). El listado de valores y formas disponibles puede verse mediantehelp(points)lty: Indica la forma en que se dibujan las líneas (continua, a trazos, …).lwd: Ancho de las líneas.col: Color usado para el gráfico (ya sea para puntos, líneas…). Puede vers un listado completo de los colores disponibles en R ejecutando la funcióncolors().help(colors)explica como obtener aún más colores. Este documento contiene una muestra de cada color.font: Fuente a usar en el texto.las: Cambia el estilo de las etiquetas de los ejes (0 paralelo a los ejes, 1 siempre horizontales, 2, perpendiculares a los ejes, 3 siempre verticales)
Ejemplos de funciones gráficas de alto nivel
Podemos destacar, entre las más utilizadas:
plot()
Esta función ofrece muchas variantes dependiendo del tipo de objeto al que se aplique. El caso más simple corresponde a la representación de dos variables x e y. En tal caso, plot(x,y) representa un diagrama de dispersión de puntos de y frente a x.
A modo de ejemplo se muestra a continuación un gráfico de la esperanza de vida (LifeExpectancy, que será nuestra variable y) frente al índice de felicidad (Happiness, que es la x) en una muestra de 143 países. Los datos se encuentran en el dataframe(HappyPlanetIndex) del paquete (Lock5Data) (consultar help(HappyPlanetIndex) para ver las variables en este dataframe, y http://www.happyplanetindex.org/about/ para más información sobre este estudio):
library(Lock5Data)
data(HappyPlanetIndex)
attach(HappyPlanetIndex)
plot(Happiness,LifeExpectancy,pch=19,col="red")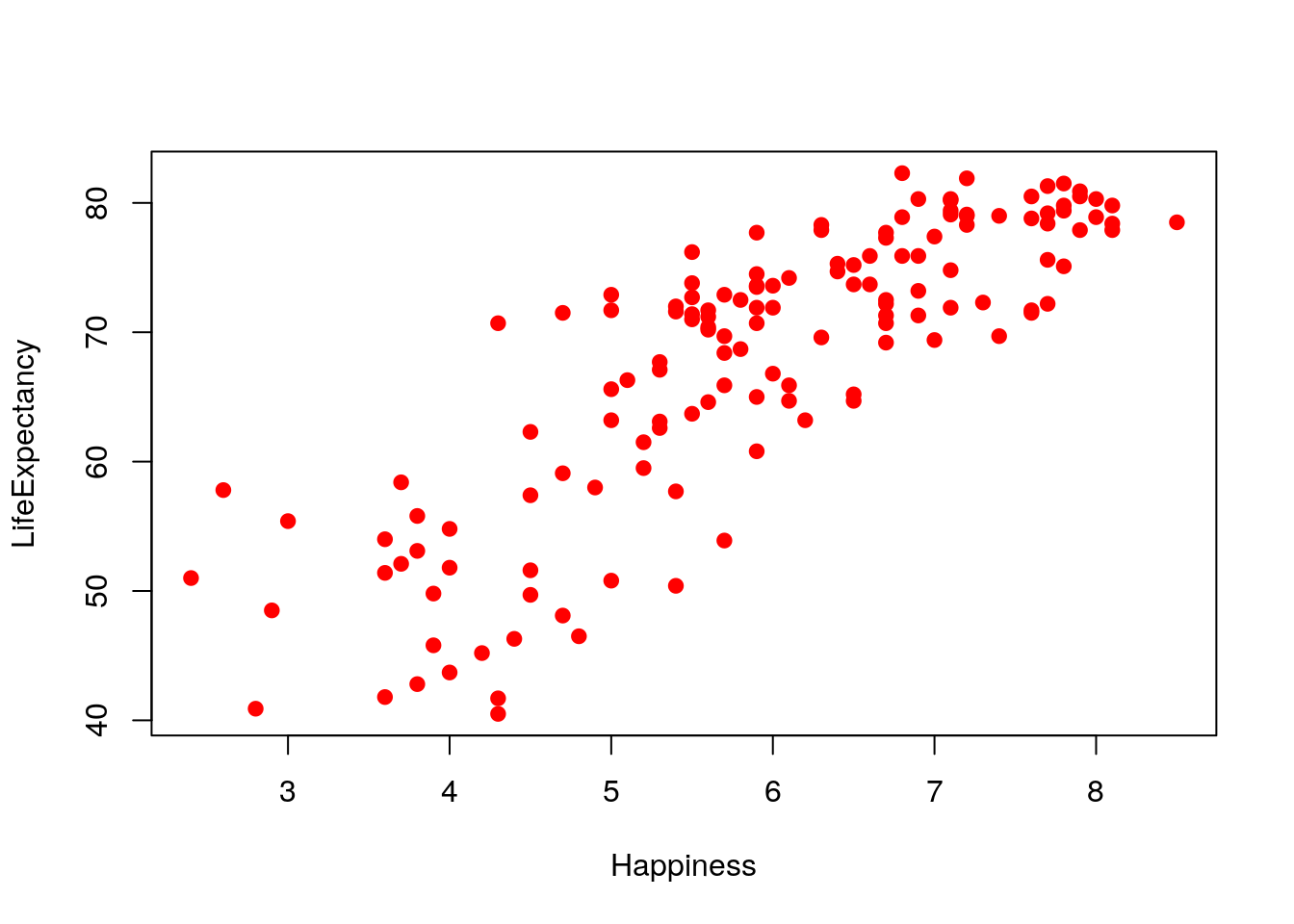
hist()
Esta función permite dibujar histogramas de frecuencias para variables continuas. Por ejemplo, el histograma de los niveles de felicidad en los distintos países de la muestra se obtiene fácilmente como:
hist(Happiness,col="darkolivegreen1")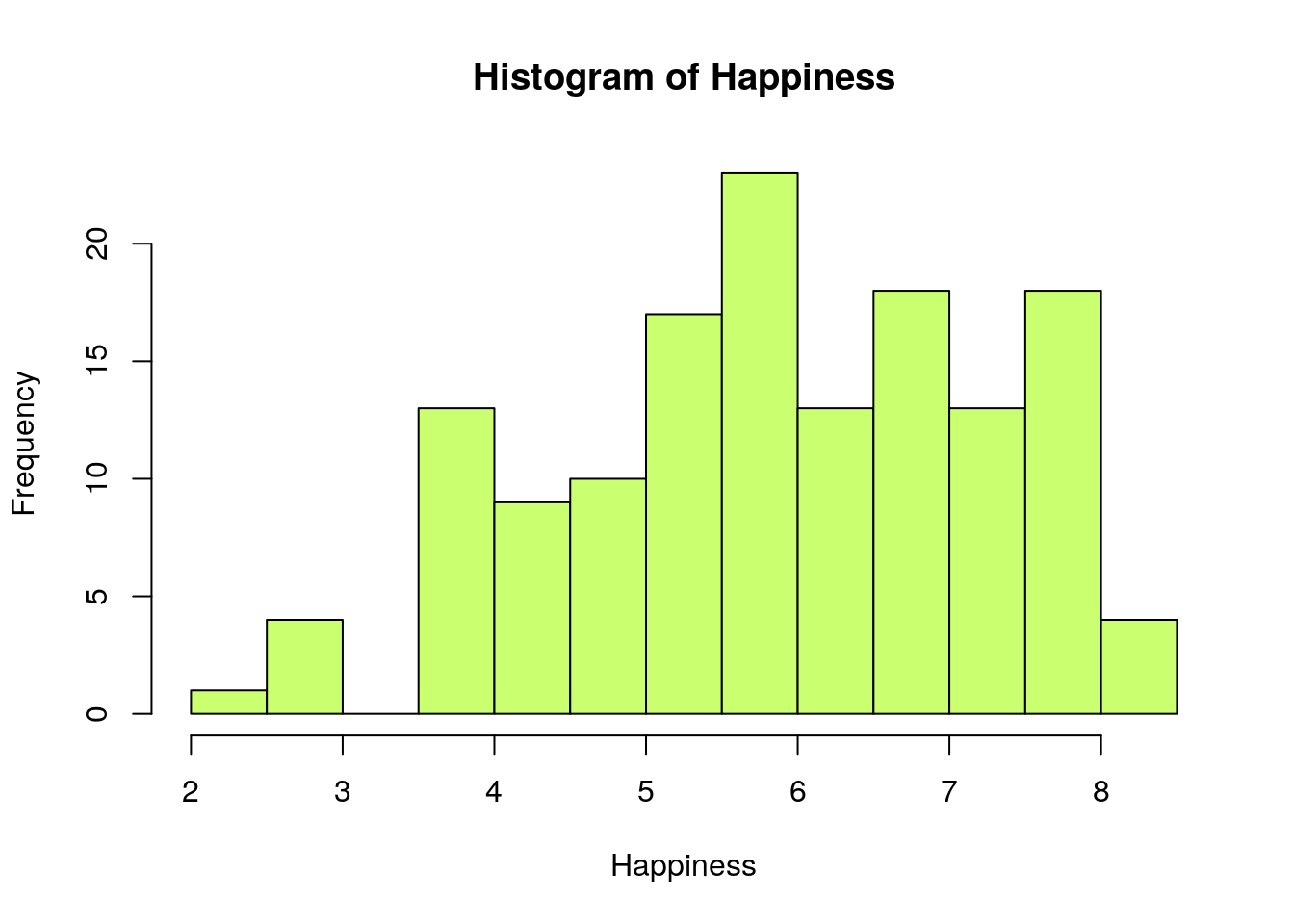
En el mismo paquete Lock5Data podemos encontrar el dataframe SalaryGender que contiene una muestra de 100 profesores universitarios de EEUU, 50 hombres y 50 mujeres; para cada uno se tiene el salario anual (en miles de dólares), la edad y la variable PhD que vale 1 si el profesor es doctor y 0 si no lo es. Podemos ver la distribución de salarios entre hombres y mujeres mediante un histograma combinado utilizando la función histStack() del paquete plotrix:
data(SalaryGender)
attach(SalaryGender)
Gender=factor(Gender,levels=c(0,1),labels=c("Female","Male"))
library(plotrix)
histStack(Salary,Gender,legend.pos="topright")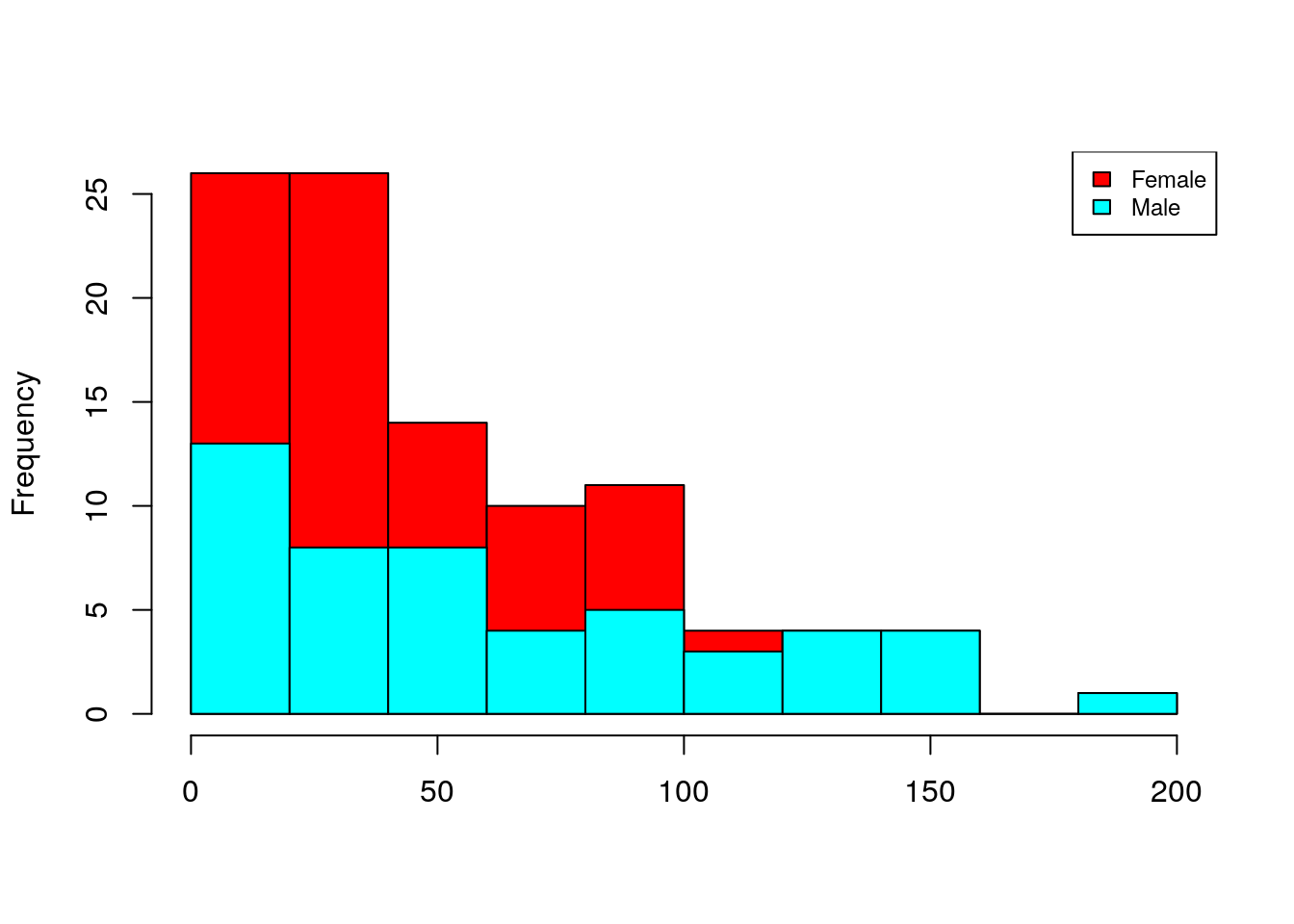
barplot()
Se utiliza para dibujar diagramas de barras. El siguiente ejemplo muestra el número de países en cada una de las 7 regiones en que se dividió el planeta para el estudio de los niveles de felicidad:
barplot(table(Region),xlab="Region",main="Happiness level by region", col=rainbow(10))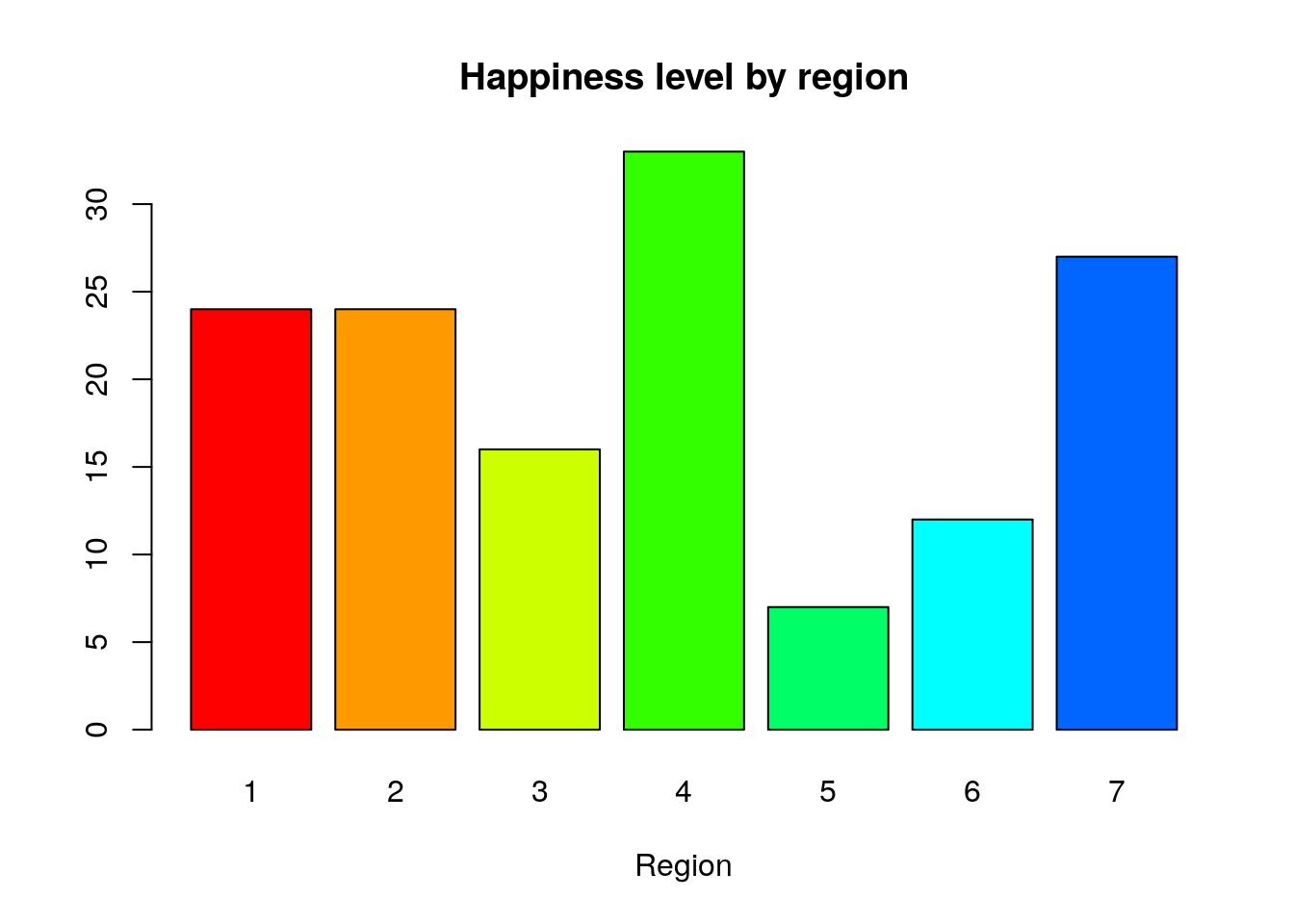
El paquete plotrix contiene la función barp() que permite dar “volumen” a la barras:
barp(table(Region),col="lightblue",cylindrical=TRUE,shadow=TRUE)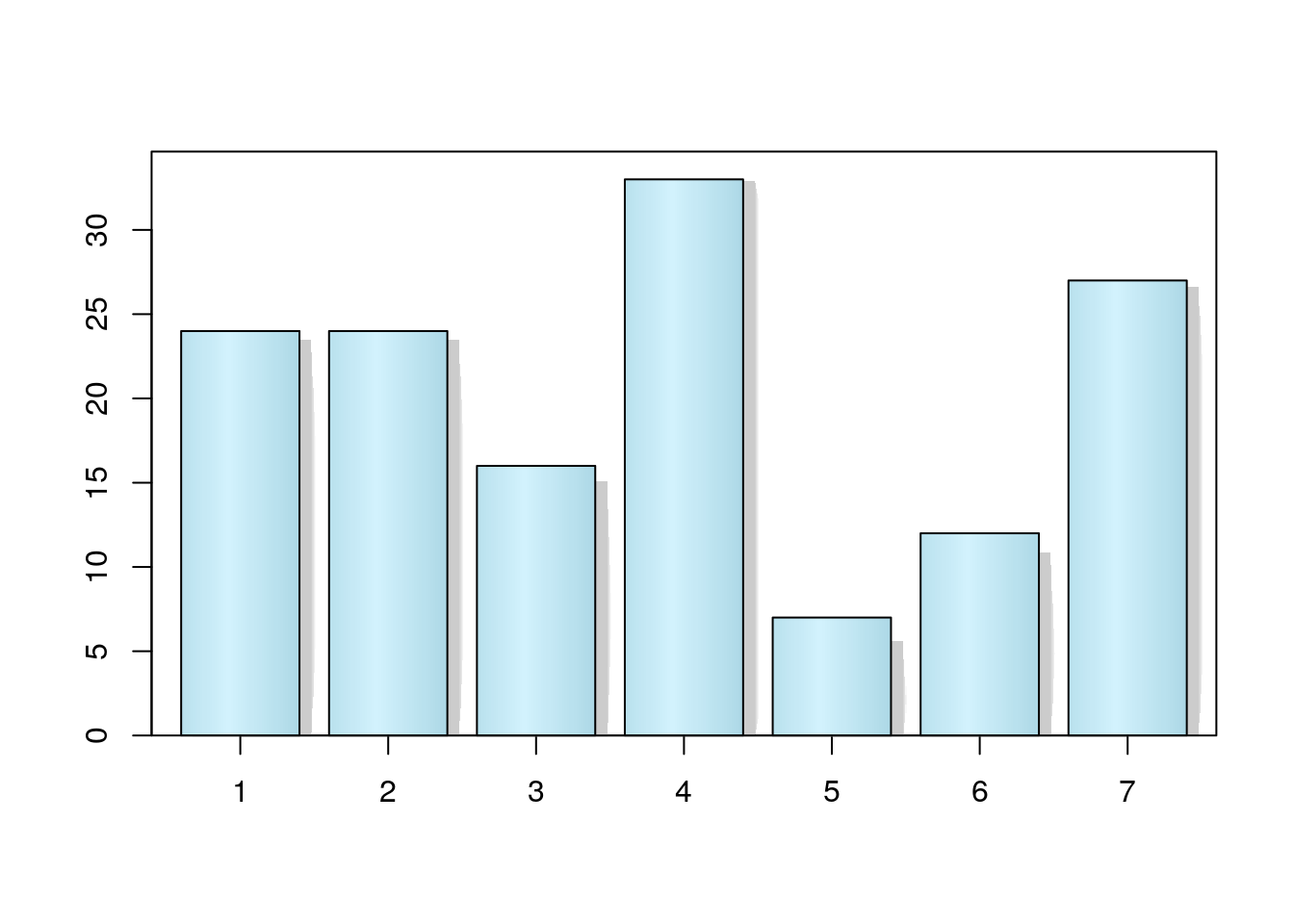
Es posible construir diagramas de barras por categorías; podemos, por ejemplo representar la frecuencia de doctores por sexo utilizando los datos del dataframe SalaryGender:
PhD=factor(PhD,levels=c(0,1),c("PhD","non PhD"))
barplot(table(Gender,PhD),beside=TRUE,legend.text=TRUE,col=c("pink","cyan"))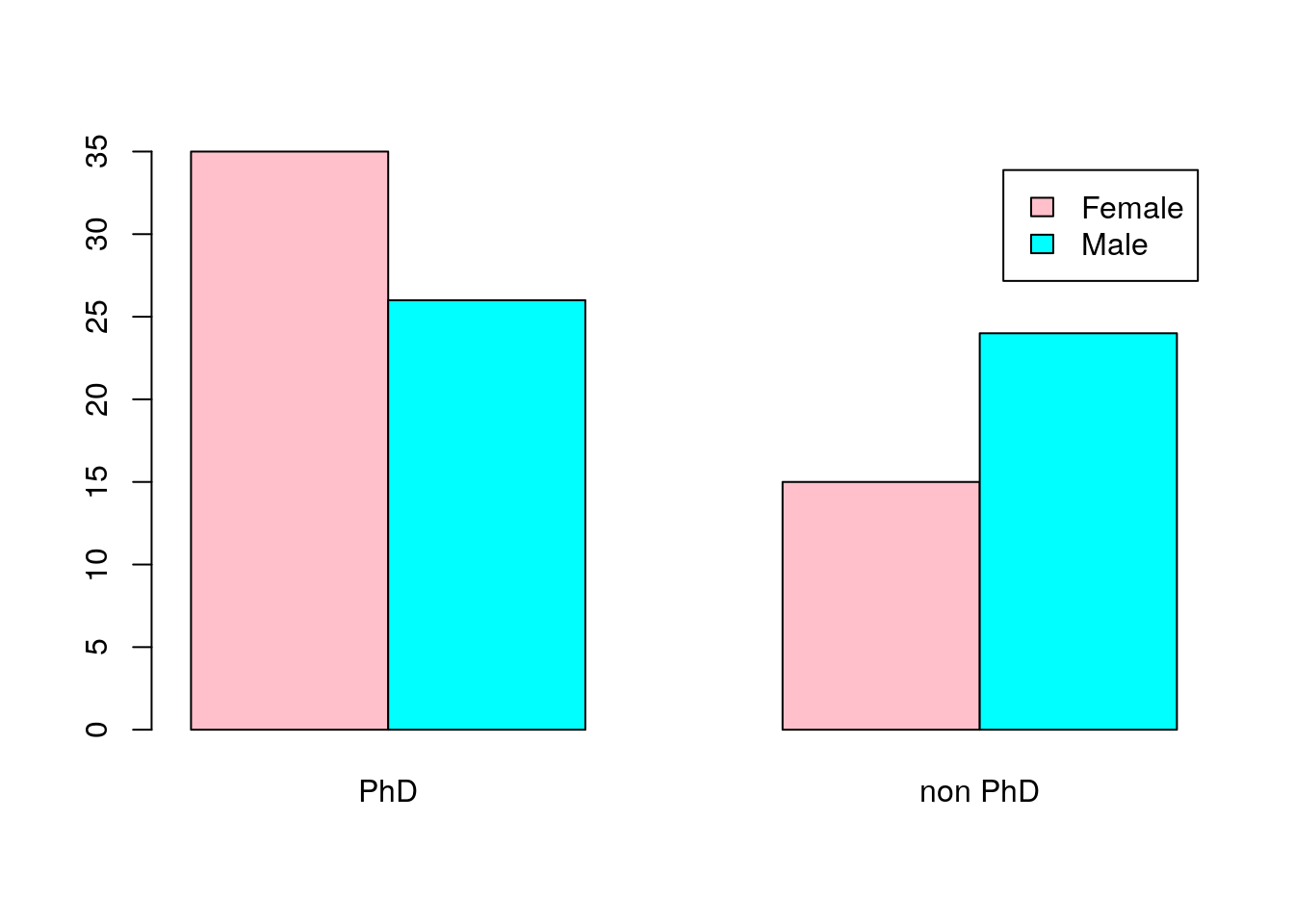
pie()
Aporta la misma información que el diagrama de barras, pero en forma de diagrama de sectores:
pie(table(Region))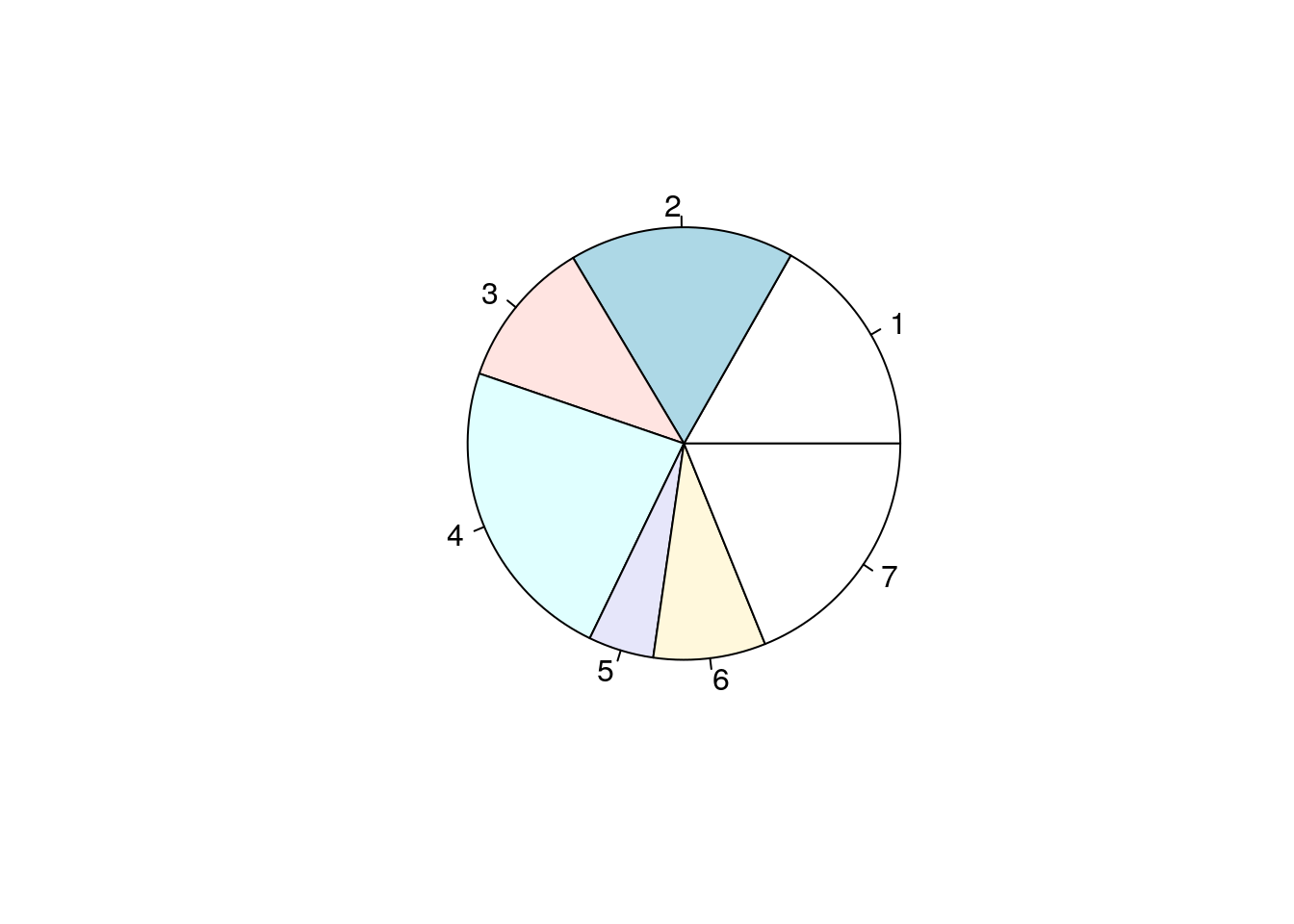
El paquete plotrix permite elaborar diagramas de sectores en 3D mediante la función pie3D:
pie3D(table(Region))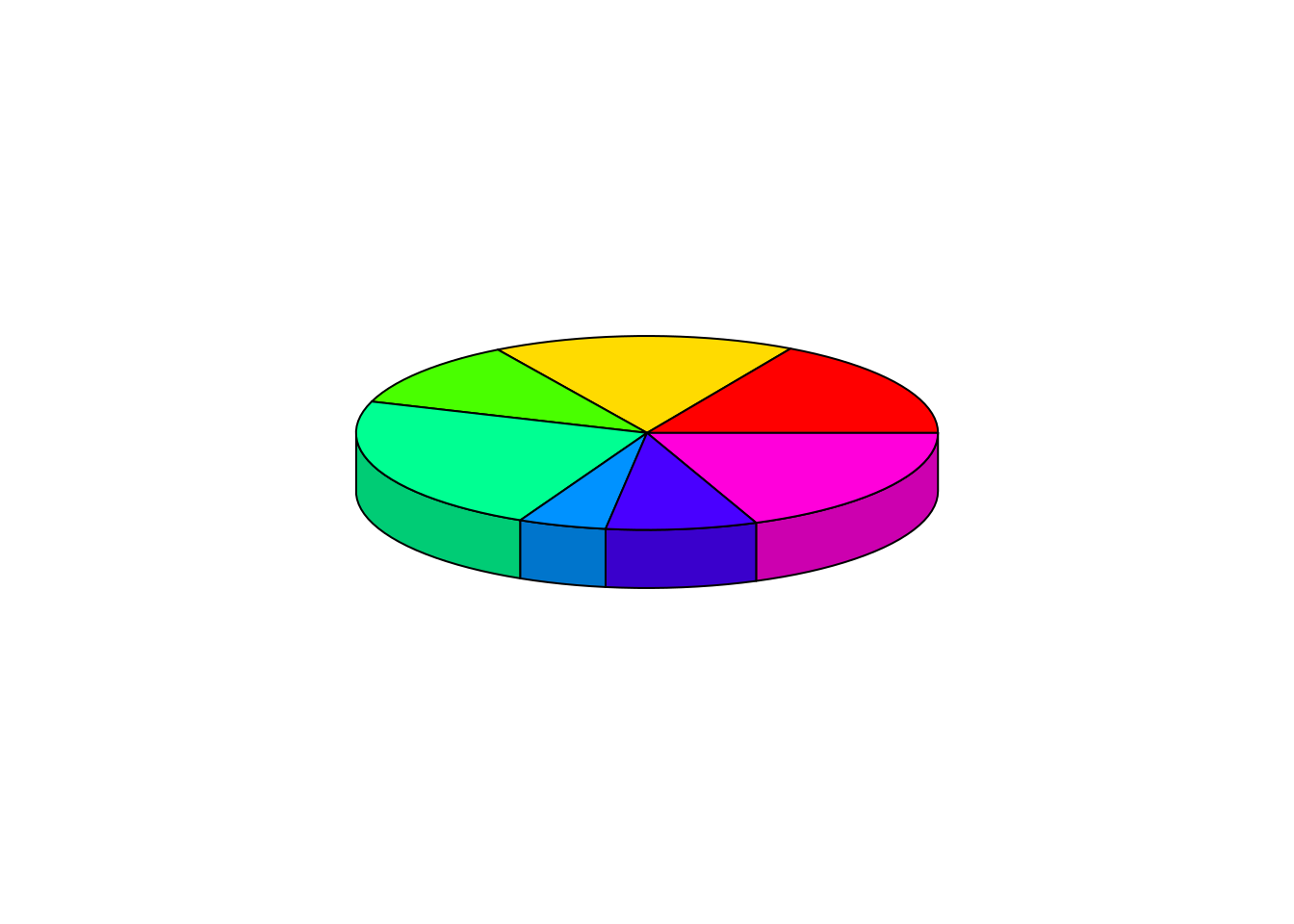
boxplot()
Lleva a cabo la representación de gráficos de “caja y bigote”. El siguiente ejemplo muestra el reparto de los niveles de felicidad entre las distintas regiones del globo:
boxplot(Happiness~Region,col="gold",xlab="Region",ylab="Happiness level",
main="Average happiness level by region")
persp()
Esta función realiza representaciones tridimensionales (superficies). El dataframe volcano que se distribuye junto con la instalación básica de R (ver help(volcano)) contiene información topográfica del volcán Maunga Whau en Auckland, Nueva Zelanda, definida sobre una malla de \(870\times 610\) metros, con un nodo cada 10 metros. Podemos trazar el perfil topográfico de este volcán mediante:
persp(x = 10*(1:nrow(volcano)), y=10*(1:ncol(volcano)), z=3*volcano,
theta = 135, phi = 30, col = "green3", scale = FALSE,
ltheta = -120, shade = 0.75, border = NA, box = FALSE, main="Volcán Maunga Whau, Auckland, NZ")
Funciones de localización e identificación de puntos: locator() e identify()
Una vez que en la ventana de gráficos tenemos algo representado, existen dos funciones que permiten trabajar interactivamente con el gráfico:
La función
locator(): al situar el cursor sobre la ventana de gráficos, cada vez que pulsemos el botón izquierdo del ratón, se almacenan en memoria las coordenadas del punto que marquemos. Al pulsar la tecla < ESC >, R nos muestra dichas coordenadas en la consola (si hemos ejecutado simplementelocator()) o las guarda en el objeto al que hayamos asignado la salida dicha función. Por ejemplo, si hemos ejecutadoposiciones=locator(), al pulsar < ESC > las coordenadas de los puntos que hayamos marcado en el gráfico se guardan en la variableposiciones.La función
identify()permite identificar con el ratón a qué posiciones dentro del conjunto de datos corresponden los puntos que señalemos en un gráfico. Si, por ejemplo, ejecutamosplot(Happiness,LifeExpectancy)para mostrar la nube de puntos de la esperanza de vida frente al índice de felicidad, y a continuación ejecutamosidentify(Happiness,LifeExpectancy)y picamos en algunos puntos del gráfico con el ratón, al pulsar < ESC >, R nos devuelve en la consola (y representa en el gráfico) los números de orden dentro del dataframe a los que corresponden los puntos que hemos marcado.
Más información
- Quick-R: Sección de gráficos de Quick-R.
- R Graphical Manual: galería de gráficos en R con su código correspondiente.
- R Graph Gallery: galería de gráficos que se pueden hacer con R y el código para obtenerlos.
- R Graphics: Imágenes de todos los gráficos del libro “R Graphics” de P. Murrell, con el código para generarlos.
- The complete ggplot tutorial
- ggplot Tutorial: Introducción a
ggplot(grammar of graphics), librería que permite realizar gráficos de alta calidad. - ggplot quick reference: guía de referencia de ggplot.
- Trellis graphics
- Ejemplos de gráficos Trellis
- Graficos tipo “comic” xkcd
- Recursos para ggplot
© 2016 Angelo Santana, Carmen N. Hernández, Departamento de Matemáticas ULPGC