Estadística Descriptiva con R
Angelo Santana & Carmen Nieves Hernández,
Departamento de Matemáticas, ULPGC
Ejercicio.
Se dispone de una muestra de 10 personas para las que se han medido las variables:
- EDAD (en años)
- SEXO (codificada como 0: “Hombre”; 1:“Mujer”)
- NIVEL DE ESTUDIOS ( 0:“Sin estudios”; 1: “Estudios Primarios”; 2: “Estudios Secundarios”; 3:“Estudios Superiores”)
Los datos se muestran en la tabla siguiente:
| edad | sexo | estudios |
|---|---|---|
| 18 | 0 | 1 |
| 19 | 1 | 2 |
| 0 | 0 | |
| 18 | 0 | 1 |
| 24 | 1 | 3 |
| 17 | 0 | 2 |
| 22 | 0 | 3 |
| 15 | 1 | 1 |
| 22 | 1 | 2 |
| 25 | 0 | 3 |
Con estos datos se desea:
Construir tablas de frecuencias unidimensionales para las tres variables.
Construir una tabla de frecuencias cruzadas con las variables ‘sexo’ y ‘nivel de estudios’.
Construir una tabla de frecuencias de la variable edad agrupada en intervalos.
Calcular media y desviación típica de la variable ‘edad’.
Calcular media y desviación típica de la variable ‘edad’ según sexo.
Representar gráficamente: el nivel de estudios en un diagrama de sectores, el sexo en un diagrama de barras y la edad en un histograma. Construir también un boxplot de la edad en función del sexo.
Introducción de datos a través de la consola.
En primer lugar introducimos los datos. Arrancamos RStudio y en el menú desplegable superior elegimos File -> New File -> R Script:
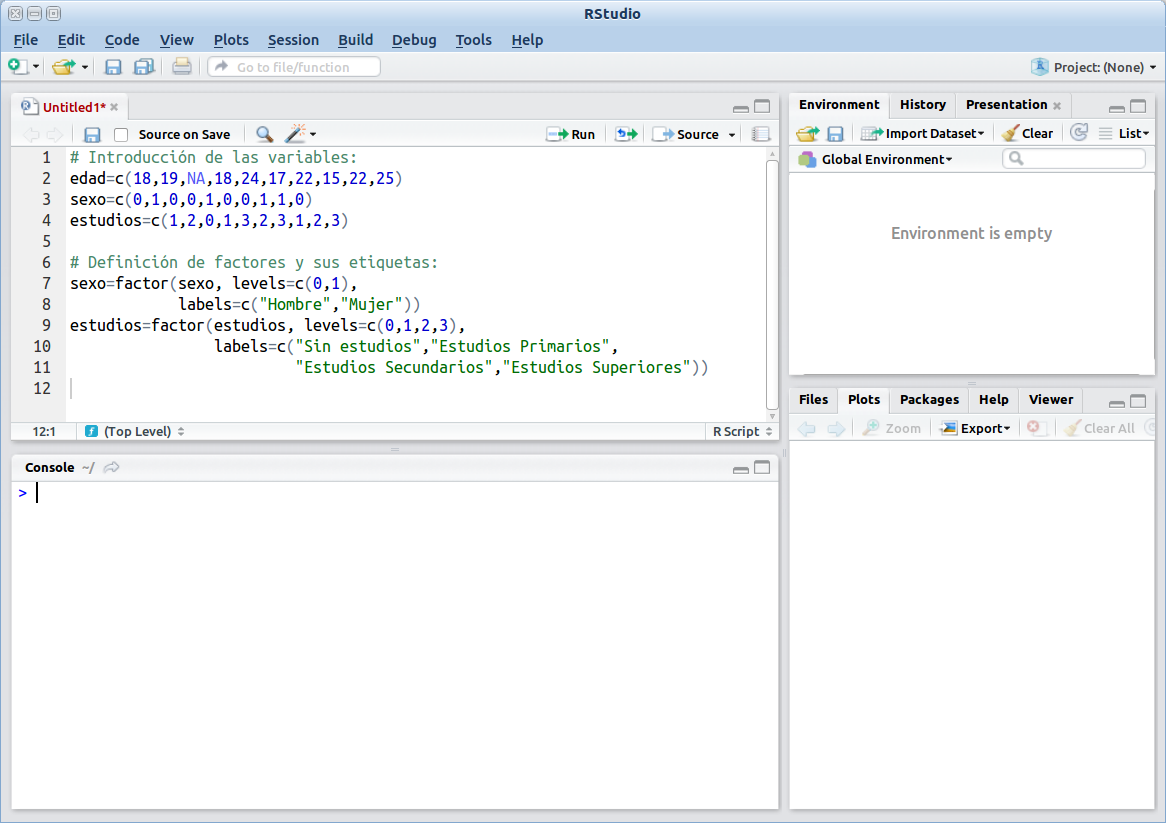
En la ventana de script construimos las variables mediante la siguiente sintaxis:
edad=c(18,19,NA,18,24,17,22,15,22,25)
sexo=c(0,1,0,0,1,0,0,1,1,0)
estudios=c(1,2,0,1,3,2,3,1,2,3)Recodificamos como factores el sexo y el nivel de estudios, asignando las etiquetas adecuadas:
sexo=factor(sexo, levels=c(0,1),
labels=c("Hombre","Mujer"))
estudios=factor(estudios, levels=c(0,1,2,3),
labels=c("Sin estudios","Estudios Primarios",
"Estudios Secundarios","Estudios Superiores"))El script debe haber quedado aproximadamente como se muestra en la figura siguiente. Por claridad, resulta conveniente que las líneas no sean demasiado largas. En este sentido, es aconsejable dividirlas respetando las comas y tratando de que su contenido resulte lo más claro posible. Además podemos incluir líneas de comentario que expliquen lo que estamos haciendo. Recordemos que las líneas de comentario deben comenzar con el símbolo #:
Análisis de los datos.
Una vez que hemos introducido los datos procedemos a resolver la tarea que nos habíamos propuesto inicialmente.
A partir de ahora, mostramos los comandos que deberemos incluir en nuestro script para que R lleve a cabo las distintas tareas, así como los resultados que se obtienen. En todos los casos dichos comandos deben introducirse en el script (debidamente comentados, si se desea) y se ejecutarán mediante  o < Ctrl-Enter >.
o < Ctrl-Enter >.
Tablas de frecuencias unidimensionales
1. Construir una tablas de frecuencias unidimensionales para las variables ‘sexo’ y ‘nivel de estudios’.
En R los comandos para la construcción de tablas son:
table(nombre_de_variable): tablas de frecuencias absolutas.prop.table(table(nombre_de_variable)): tablas de frecuencias relativas. Nótese aquí que la funciónprop.table()no opera directamente sobre la variable, sino sobre la tabla de frecuencias absolutas creada contable()!!. Esta es una característica habitual de R: utilizar funciones que operan sobre objetos creados previamente por otras funciones.
table(edad)## edad
## 15 17 18 19 22 24 25
## 1 1 2 1 2 1 1prop.table(table(edad))## edad
## 15 17 18 19 22 24 25
## 0.111111 0.111111 0.222222 0.111111 0.222222 0.111111 0.111111Nótese que, por defecto, R no muestra cuantos valores perdidos hay en los datos. Para ello debemos utilizar la opción useNA="ifany":
table(edad,useNA="ifany")## edad
## 15 17 18 19 22 24 25 <NA>
## 1 1 2 1 2 1 1 1
TRABAJO AUTÓNOMO: Construye tablas de frecuencias para las variables sexo y Nivel de estudios
Tablas de frecuencias cruzadas
2. Construir una tabla de frecuencias cruzadas con las variables anteriores.
Las tablas de frecuencias cruzadas se construyen también con las funciones table() y prop.table(table()), especificando ahora las dos variables a cruzar. Para las frecuencias relativas, en prop.table() incluimos un 1 si las queremos por filas, un 2 si por columnas, o nada si queremos las frecuencias relativas globales:
table(estudios,sexo)## sexo
## estudios Hombre Mujer
## Sin estudios 1 0
## Estudios Primarios 2 1
## Estudios Secundarios 1 2
## Estudios Superiores 2 1prop.table(table(estudios,sexo))## sexo
## estudios Hombre Mujer
## Sin estudios 0.1 0.0
## Estudios Primarios 0.2 0.1
## Estudios Secundarios 0.1 0.2
## Estudios Superiores 0.2 0.1prop.table(table(estudios,sexo),1)## sexo
## estudios Hombre Mujer
## Sin estudios 1.000000 0.000000
## Estudios Primarios 0.666667 0.333333
## Estudios Secundarios 0.333333 0.666667
## Estudios Superiores 0.666667 0.333333prop.table(table(estudios,sexo),2)## sexo
## estudios Hombre Mujer
## Sin estudios 0.166667 0.000000
## Estudios Primarios 0.333333 0.250000
## Estudios Secundarios 0.166667 0.500000
## Estudios Superiores 0.333333 0.250000Nótese que hemos tenido que escribir mucho para obtener estas tablas. Cuando un objeto en R se repite muchas veces, resulta conveniente asignarle un nombre que nos permita acceder a él fácilmente. Así, en este caso, podíamos haber construido las tablas anteriores mediante:
t=table(estudios,sexo)
prop.table(t)
prop.table(t,1)
prop.table(t,2)Tabla de frecuencias de una variable continua agrupada en intervalos.
La función:
range(edad,na.rm=TRUE) # incluimos na.rm=TRUE para que ignore la presencia de valores perdidos## [1] 15 25nos indica que los valores de edad se sitúan en el rango de 15 a 25 años. Para construir los intervalos de edad podemos utilizar la regla de Sturges, que nos proporciona un número adecuado de intervalos en función del rango de los datos (ver help(nclass.Sturges); de modo alternativo podría utilizarse la regla de Scott o la de Freedman-Diaconis). Una vez que hemos decidido el número de intervalos, generamos una secuencia de valores con los límites de cada intervalo y utilizamos la función cut() para que nos construya una nueva variable que recodifica la edad en dichos intervalos:
nclass.Sturges(edad) # Número de intervalos## [1] 5seq(15,25,length=nclass.Sturges(edad)) # Límites de los intervalos## [1] 15.0 17.5 20.0 22.5 25.0# Construcción de los intervalos mediante la función cut():
intervalosEdad=cut(edad,breaks=seq(15,25,length=nclass.Sturges(edad)),include.lowest=TRUE)
intervalosEdad # Se muestran los intervalos de edad, uno correspondiente a cada edad observada## [1] (17.5,20] (17.5,20] <NA> (17.5,20] (22.5,25] [15,17.5] (20,22.5]
## [8] [15,17.5] (20,22.5] (22.5,25]
## Levels: [15,17.5] (17.5,20] (20,22.5] (22.5,25]Por último construimos la tabla de frecuencias de esta variable:
table(intervalosEdad)## intervalosEdad
## [15,17.5] (17.5,20] (20,22.5] (22.5,25]
## 2 3 2 2El paquete agricolae incluye la función table.freq() que construye la tabla de frecuencias para variables agrupadas en intervalos a partir de la información generada por la función hist() del paquete base de R. Esta función dibuja un histograma; como no nos interesa en este momento, añadimos la opción plot=FALSE:
library(agricolae)
tbFreqEdad=table.freq(hist(edad,plot=FALSE))
tbFreqEdad## Lower Upper Main Frequency Percentage CF CPF
## 1 14 16 15 1 11.1 1 11.1
## 2 16 18 17 3 33.3 4 44.4
## 3 18 20 19 1 11.1 5 55.6
## 4 20 22 21 2 22.2 7 77.8
## 5 22 24 23 1 11.1 8 88.9
## 6 24 26 25 1 11.1 9 100.0Estadísticos descriptivos
4. Calcular media y desviación típica de la variable ‘edad’.
Las funciones disponibles en R para calcular estos estadísticos descriptivos son, respectivamente, mean(nombre_de_variable) y sd(nombre_de_variable):
mean(edad)## [1] NAsd(edad)## [1] NA¿Qué ha ocurrido aquí?
NA es el acrónimo para Not Available, esto es, para valores perdidos. Como la variable edad tiene valores perdidos, R “no puede” calcular su media ni su desviación típica, devolviéndonos un valor perdido. De alguna manera R está “avisando” para que tengamos precaución (imaginemos que hemos medido 100 sujetos y sólo tenemos la edad de uno de ellos; la media sería ese único valor por lo que podría no estar describiendo adecuadamente la media de los datos). ¿Cómo hacer para “obligar” a R a que nos calcule la media y la desviación típica en presencia de valores perdidos?
TRABAJO AUTÓNOMO: Ejecuta help(mean) en la linea de comandos. Consulta la ayuda para descubrir de qué forma se consigue que R calcule la media en presencia de valores perdidos.
R dispone de una función genérica summary(), que cuando se aplica a una variable presenta un pequeño resumen descriptivo. Si la variable es numérica, dicho resumen incluye el mínimo, máximo, mediana, primer y tercer cuartiles, media y número de valores perdidos. Si la variable es de tipo factor, summary() muestra el número de observaciones en cada nivel del factor:
summary(edad)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 15 18 19 20 22 25 1summary(estudios)## Sin estudios Estudios Primarios Estudios Secundarios
## 1 3 3
## Estudios Superiores
## 3summary(sexo)## Hombre Mujer
## 6 4Si las variables están contenidas en un data.frame la aplicación de summary() lleva a cabo un resumen descriptivo de todas las variables que contiene:
misDatos=data.frame(edad,estudios,sexo)
summary(misDatos)## edad estudios sexo
## Min. :15 Sin estudios :1 Hombre:6
## 1st Qu.:18 Estudios Primarios :3 Mujer :4
## Median :19 Estudios Secundarios:3
## Mean :20 Estudios Superiores :3
## 3rd Qu.:22
## Max. :25
## NA's :1
TRABAJO AUTÓNOMO: Ejecuta la función describe(misDatos) (debes cargar previamente la librería psych mediante library(psych)), y observa como ahora la descripción se aplica a todas las variables de este data.frame.
Resúmenes de datos por grupos.
5. Calcular media y desviación típica de la variable ‘edad’ por sexo.
Para ello utilizamos la función aggregate():
aggregate(edad,by=list(sexo),mean)## Group.1 x
## 1 Hombre NA
## 2 Mujer 20En el caso de los hombres nos encontramos nuevamente con el problema de los valores perdidos. Para obtener el resultado prescindiendo de dichos valores, es preciso utilizar la opción na.rm=TRUE (na.rm es un acrónimo de na remove):
aggregate(edad,by=list(sexo),mean,na.rm=TRUE)## Group.1 x
## 1 Hombre 20
## 2 Mujer 20Existen algunas librerías o paquetes que contienen funciones más elaboradas para la obtención de estadísticos descriptivos de manera sencilla. Por ejemplo, la librería psych contiene las funciones describe() y describe.by() que no sólo calculan la media sino que añaden otros estadísticos de interés.
TRABAJO AUTÓNOMO Ejecuta los siguientes comandos (debes cargar primero la librería psych si no lo has hecho antes), y observa el resultado:
describe(edad)
describeBy(edad,sexo)Representaciones gráficas
6. Representar gráficamente: el nivel de estudios en un diagrama de sectores, el sexo en un diagrama de barras y la edad en un histograma. Construir también un boxplot de la edad en función del sexo.
Esta tarea puede llevarse a cabo de manera muy simple mediante los comandos que se muestran a continuación. Nótese que tanto para el diagrama de sectores (pie()) como para el diagrama de barras (barplot()) el argumento que se requiere es la tabla de frecuencias obtenida mediante table():
pie(table(estudios))
barplot(table(sexo))
hist(edad)
boxplot(edad~sexo)
TRABAJO AUTÓNOMO
Ejecuta
help(pie)y averigua cómo se puede poner un título al gráfico de sectores. Repite este gráfico, esta vez con el título “Distribución del nivel de estudios”Colorea los sectores de modo diferente: utiliza la opción
col=c("red","blue","green","yellow")Teclea
colors()para ver una lista de los colores disponibles para los gráficos.Dibuja un diagrama de barras para sexo con las barras horizontales y con un color distinto para cada sexo. Ayúdate de
help(barplot)Cambia el título del histograma de edades, de forma que diga “Distribución por edades”. Explora la ayuda del comando
hist()para que el histograma se construya en frecuencias relativas, y las barras se levanten sobre los intervalos (14,17], (17,20], (20,23] y (23,26].
© 2016 Angelo Santana, Carmen N. Hernández, Departamento de Matemáticas ULPGC