Creación, Importación y Exportación de datos
Angelo Santana & Carmen Nieves Hernández,
Departamento de Matemáticas, ULPGC
Ejemplo
Se dispone de una muestra de 10 personas para las que se han medido las variables:
- EDAD (en años)
- SEXO (codificada como 0: “Hombre”; 1:“Mujer”)
- NIVEL DE ESTUDIOS ( 0:“Sin estudios”; 1: “Estudios Primarios”; 2: “Estudios Secundarios”; 3:“Estudios Superiores”)
Los datos se muestran en la tabla siguiente:
| edad | sexo | estudios |
|---|---|---|
| 18 | 0 | 1 |
| 19 | 1 | 2 |
| 0 | 0 | |
| 18 | 0 | 1 |
| 24 | 1 | 3 |
| 17 | 0 | 2 |
| 22 | 0 | 3 |
| 15 | 1 | 1 |
| 22 | 1 | 2 |
| 25 | 0 | 3 |
En esta sección veremos distintas maneras en que podemos conseguir que estos datos estén accesibles para R, de forma que podamos trabajar con ellos cómodamente.
Creación de la base de datos.
R no dispone de un editor de datos como SPSS.
¿COMO CREAMOS NUESTRA BASE DE DATOS EN R?
Tenemos múltiples opciones:
Si son pocos datos: Introducir los datos directamente en la consola de R.
Si son muchos datos: Podemos utilizar casi cualquier soporte:
* Excel * SPSS * PSPP * Libreoffice Calc * Access * MySQL * ...
Para los usuarios acostumbrados a utilizar SPSS como herramienta habitual para la introducción y gestión de datos, el programa PSPP puede resultar particularmente cómodo, ya que su aspecto y funcionamiento es muy similar al de SPSS. PSPP es software libre y puede descargarse de la dirección http://www.gnu.org/software/pspp/, donde existen versiones para todos los sistemas operativos. Mostramos a continuación la ventana de entrada de datos de PSPP:
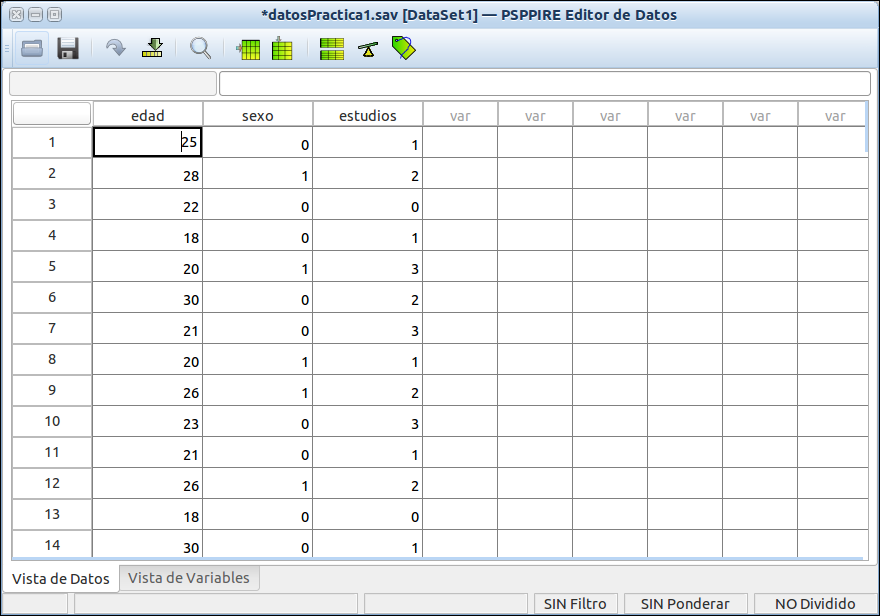
Citemos aquí también que como alternativa de software libre a Excel podemos utilizar LibreOffice (u OpenOffice) calc, que puede descargarse de http://es.libreoffice.org/descarga/.
Introducción de datos a través de la consola.
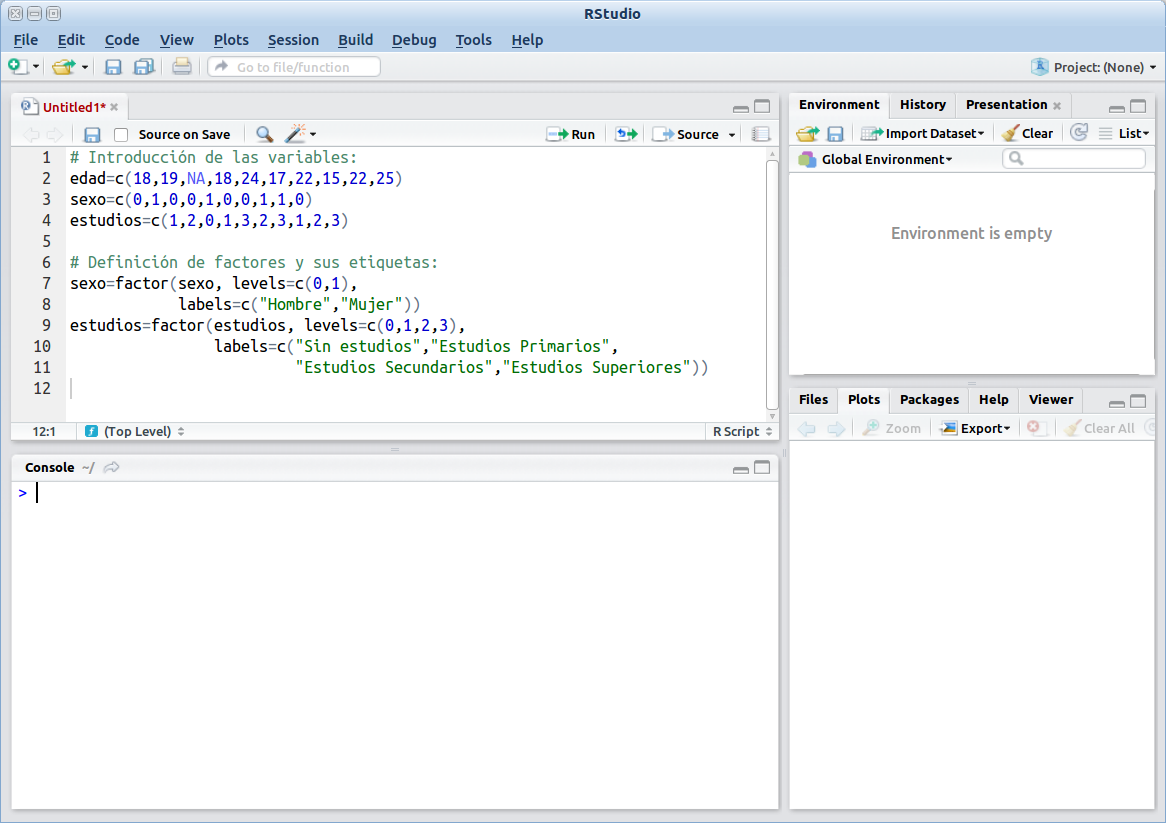
Esta opción resulta aconsejable solamente en aquellas ocasiones en que manejamos un volumen muy reducido de datos (pocas variables y pocos casos como en el ejemplo de más arriba). Como siempre, resultará conveniente abrir un nuevo R script en Rstudio y declarar allí las variables. Para ello arrancamos RStudio y en el menú desplegable superior elegimos File -> New File -> R Script. En la ventana de script comenzamos declarando nuestras variables mediante la función de concatenación c():
edad=c(18,19,NA,18,24,17,22,15,22,25)
sexo=c(0,1,0,0,1,0,0,1,1,0)
estudios=c(1,2,0,1,3,2,3,1,2,3)En R (al menos en el paquete base) no es posible asignar etiquetas a los nombres de variable, por lo que conviene que dichos nombres sean muy claros. Para aclarar el significado de los valores de las variables categóricas (sexo y nivel de estudios) las convertimos en factores y asignamos etiquetas a sus valores mediante la función factor():
sexo=factor(sexo, levels=c(0,1),
labels=c("Hombre","Mujer"))
estudios=factor(estudios, levels=c(0,1,2,3),
labels=c("Sin estudios","Estudios Primarios",
"Estudios Secundarios","Estudios Superiores"))El script debe haber quedado aproximadamente como se muestra en la figura siguiente. Por claridad, resulta conveniente que las líneas no sean demasiado largas. En este sentido, es aconsejable dividirlas respetando las comas y tratando de que su contenido resulte lo más claro posible. Además podemos incluir líneas de comentario que expliquen lo que estamos haciendo. Las líneas de comentario deben comenzar con el símbolo #:
Ahora bien, la estructura natural para los conjuntos de datos en R es el data.frame. Un data.frame es, en esencia, una matriz en la que cada fila representa un caso y cada columna una variable. Las columnas de un data.frame habitualmente tienen el nombre de la variable que representan. A diferencia de una matriz, en la que todos sus valores deben ser del mismo tipo, un data.frame puede contener variables de distinta naturaleza (enteras, reales, de tipo carácter, factores, lógicas,…).
Muchos procedimientos de R están diseñados específicamente para operar sobre data.frames, por lo que su uso resulta extremadamente aconsejable.
Podemos crear un data.frame con las tres variables consideradas utilizando la siguiente sintaxis:
misDatos=data.frame(edad,sexo,estudios)Podemos mostrar el contenido de este data.frame simplemente introduciendo su nombre en la consola y pulsando ENTER:
misDatos## edad sexo estudios
## 1 18 Hombre Estudios Primarios
## 2 19 Mujer Estudios Secundarios
## 3 NA Hombre Sin estudios
## 4 18 Hombre Estudios Primarios
## 5 24 Mujer Estudios Superiores
## 6 17 Hombre Estudios Secundarios
## 7 22 Hombre Estudios Superiores
## 8 15 Mujer Estudios Primarios
## 9 22 Mujer Estudios Secundarios
## 10 25 Hombre Estudios SuperioresLa función str(nombre_del_data.frame) nos muestra la estructura del data.frame que nos permite comprobar si su construcción se ha realizado correctamente:
str(misDatos)## 'data.frame': 10 obs. of 3 variables:
## $ edad : num 18 19 NA 18 24 17 22 15 22 25
## $ sexo : Factor w/ 2 levels "Hombre","Mujer": 1 2 1 1 2 1 1 2 2 1
## $ estudios: Factor w/ 4 levels "Sin estudios",..: 2 3 1 2 4 3 4 2 3 4
Habiendo procedido de este modo, tendremos ahora en nuestro entorno de trabajo las tres variables edad, estudios y sexo, así como el dataframe misDatos. Podemos ver el entorno de trabajo en la ventana superior derecha de Rstudio, tal como se muestra en la imagen siguiente.
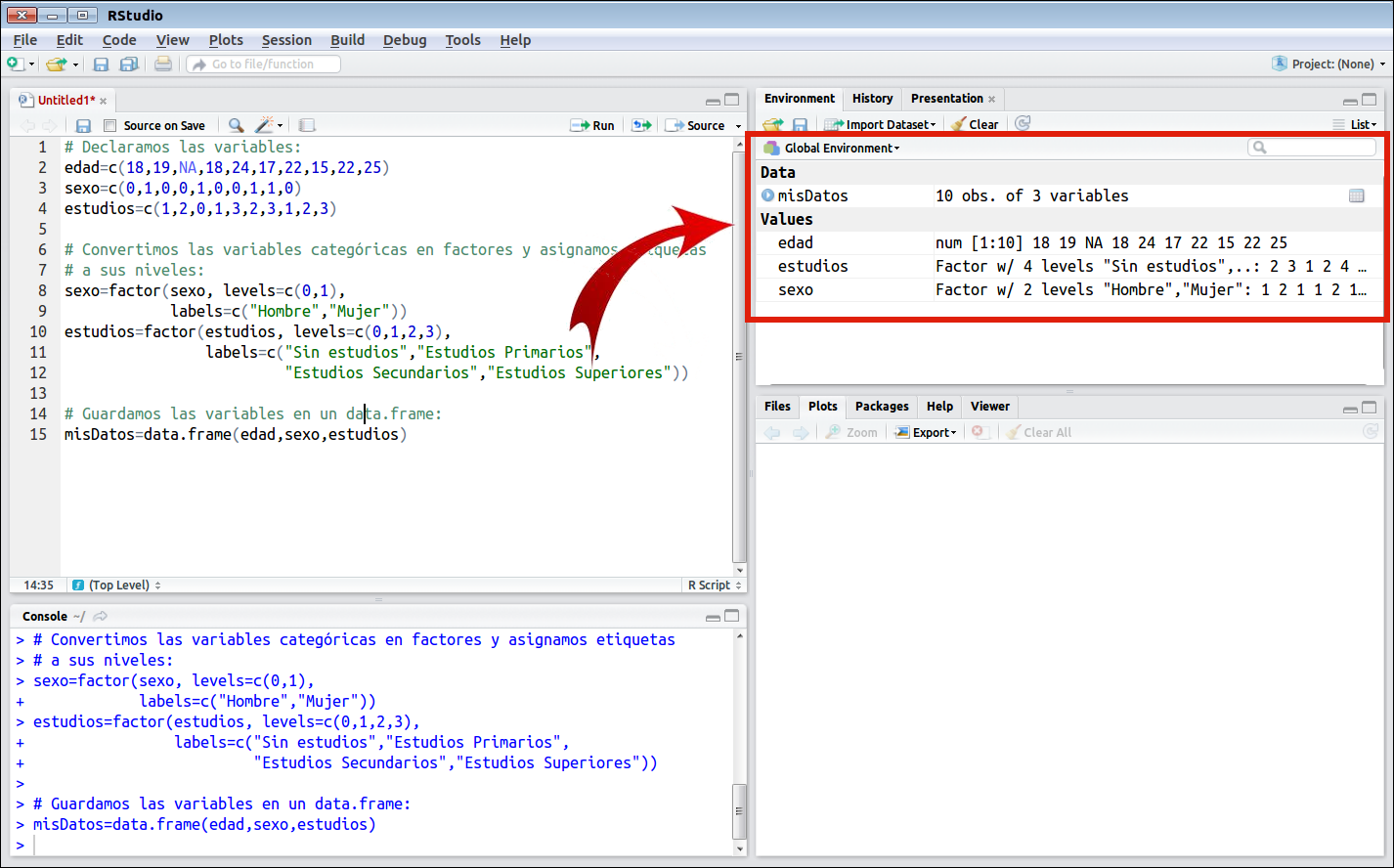
Entorno de trabajo
Como las tres variables ya están incluidas en el dataframe misDatos, podemos eliminarlas del entorno de trabajo mediante la función rm() (remove):
rm(edad, sexo, estudios)Exportación de datos a archivos externos
Estos datos pueden guardarse en un archivo externo de varias formas. En primer lugar reunimos todas las variables en un único objeto (matriz de datos o data.frame):
misDatos=data.frame(edad,sexo,estudios)
misDatos## edad sexo estudios
## 1 18 Hombre Estudios Primarios
## 2 19 Mujer Estudios Secundarios
## 3 NA Hombre Sin estudios
## 4 18 Hombre Estudios Primarios
## 5 24 Mujer Estudios Superiores
## 6 17 Hombre Estudios Secundarios
## 7 22 Hombre Estudios Superiores
## 8 15 Mujer Estudios Primarios
## 9 22 Mujer Estudios Secundarios
## 10 25 Hombre Estudios SuperioresAhora averigüemos cual es nuestro directorio por defecto:
getwd() # Acrónimo de 'get working directory'## [1] "/home/cursoR"Si quisiéramos guardar los datos en otro directorio distinto podríamos cambiar a dicho directorio:
setwd("nombre-directorio")Exportación de los datos en el formato propio de R (.rdata)
save(misDatos,file="miArchivoDeDatos.rdata")Exportación de datos en formato csv.
El formato csv es un formato de texto plano que manejan habitualmente todos los programas que gestionan hojas de cálculo (Excel, LibreOffice, etc). Estos programas son capaces tanto de leer como de guardar (utilizando la opción Guardar como) archivos en ese formato.
En el formato csv anglosajón, los campos están separados por comas y el símbolo decimal es un punto. En el formato csv latino los campos se separan por punto y coma, y el símbolo decimal es la coma. En el caso de utilizar Excel en español, si le pedimos que guarde el fichero en formato csv, lo hará en el formato latino.
Para guardar con R nuestros datos en el formato csv latino empleamos el comando write.csv2():
write.csv2(misDatos,file="miArchivoDeDatos.csv")(Si quisiéramos guardar los datos en formato .csv anglosajón utilizaríamos write.csv()).
Si ahora miramos el contenido del directorio donde hemos guardado este archivo podemos comprobar que el archivo “miArchivoDeDatos.csv” aparece en ese directorio. Pinchando dos veces sobre el archivo, se abrirá por defecto en Excel (en caso de usar Windows y tener Excel instalado). Puede ahora utilizarse Excel para editarlo, añadir datos, borrarlos, etc.
Los comandos write.csv() y write.csv2() son, en realidad, formas simplificadas de llamar a la función write.table(). Esta función es más general y permite guardar datos especificando el símbolo decimal a utilizar, el símbolo que se emplea para separar los valores, el símbolo para especificar las variables tipo carácter, nombres de fila y columna, etc. A modo de ejemplo, el comando write.csv2() que hemos utilizado anteriormente es equivalente a:
write.table(misDatos,file="miArchivoDeDatos.csv", sep=";", dec=",")Importación de datos desde archivos externos a R
R puede importar datos desde múltiples plataformas (Hojas de cálculo, bases de datos, SPSS, …). En el caso particular de que se importen datos desde una hoja de cálculo es recomendable que los datos estén colocados de tal forma que cada columna corresponda a una variable y cada fila a un caso, reservando la primera fila para los nombres de variables.
Importación de los datos desde un archivo Excel
Podemos utilizar la librería XLConnect. Una vez cargada la librería, la lectura de los datos se realiza en dos pasos:
Cargamos el libro excel mediante
loadWorkbook(nombre_del_archivo_excel).Leemos la hoja concreta donde están los datos (si no sabemos qué hojas contiene el libro podemos averiguarlo mediante la función
getSheets())
Para descargar el fichero de datos Aquí
library(XLConnect)
miLibroXLS=loadWorkbook("datosPractica1.xlsx")
getSheets(miLibroXLS) # Nos muestra los nombres de las hojas en el archivo excel
misDatos1=readWorksheet(miLibroXLS,sheet="Hoja1")Podemos comprobar cuál es la estructura de los datos que hemos leído mediante str(); asimismo, mediante la función head() podemos ver las primeras filas de datos:
str(misDatos1)## 'data.frame': 200 obs. of 3 variables:
## $ edad : int 46 37 34 38 34 43 27 47 28 36 ...
## $ sexo : int 1 1 1 1 0 0 0 1 1 1 ...
## $ estudios: int 3 0 2 1 1 0 0 0 2 2 ...head(misDatos1)## edad sexo estudios
## 1 46 1 3
## 2 37 1 0
## 3 34 1 2
## 4 38 1 1
## 5 34 0 1
## 6 43 0 0Otra librería que podemos utilizar es readxl
library(readxl)
misDatos1=read_excel("datos/datosPractica1.xlsx")
head(misDatos1)## # A tibble: 6 x 3
## edad sexo estudios
## <dbl> <dbl> <dbl>
## 1 46 1 3
## 2 37 1 0
## 3 34 1 2
## 4 38 1 1
## 5 34 0 1
## 6 43 0 0Exportación a archivos Excel
NOTA: aunque no lo hemos citado en la sección de exportación de datos, exportar datos en Excel es también muy sencillo con la librería XLConnect. Si queremos guardar los datos anteriores en un libro Excel con el nombre practicaExcel.xlxs ejecutamos los siguientes comandos:
wb <- loadWorkbook("practicaExcel.xlsx", create = TRUE) # Crea la estructura del libro de Excel
createSheet(wb, name = "practica1") # Añade una hoja llamada practica1
writeWorksheet(wb, misDatos1, sheet = "practica1") # Escribe los datos en esa hoja
saveWorkbook(wb) # Cierra el libro Excel y lo guarda en discoPosibles problemas de memoria al leer archivos Excel
En ocasiones el archivo Excel a leer (o escribir) es muy grande y puede exceder la capacidad de memoria que reserva la librería XLConnect. Ello es debido a que dicha librería copia la hoja de cálculo íntegra en una máquina virtual java, (JVM) antes de convertirla en un data.frame. Es posible, si el archivo es muy grande, que la memoria reservada a dicha máquina virtual sea insuficiente, en cuyo caso se muestra el mensaje:
Error : OutOfMemoryError ( Java ): Java heap space
Para evitar esta situación es preciso inicializar el tamaño de la memoria asignada a la JVM antes de llamar a la librería XLConnect, mediante:
options(java.parameters = "-Xmx4g" )
library(XLConnect)Importación desde un archivo .sav del SPSS
En este caso utilizaremos la librería foreign, que contiene la función read.spss(). En este ejemplo leemos el archivo directamente desde una dirección de internet, aunque lo habitual será leerlo desde alguna carpeta de nuestro disco:
library(foreign)
misDatos2=read.spss("http://www.dma.ulpgc.es/profesores/personal/stat/cursoR4ULPGC/datos/datosPractica1.sav", to.data.frame=TRUE)str(misDatos2)## 'data.frame': 200 obs. of 3 variables:
## $ edad : num 25 28 22 18 20 30 21 20 26 23 ...
## $ sexo : Factor w/ 2 levels "Hombre","Mujer": 1 2 1 1 2 1 1 2 2 1 ...
## $ estudios: Factor w/ 4 levels "Sin estudios",..: 2 3 1 2 4 3 4 2 3 4 ...
## - attr(*, "variable.labels")= Named chr "Edad en años" "" "Nivel de estudios"
## ..- attr(*, "names")= chr "edad" "sexo" "estudios"
## - attr(*, "codepage")= int 65001head(misDatos2)## edad sexo estudios
## 1 25 Hombre Estudios Primarios
## 2 28 Mujer Estudios Secundarios
## 3 22 Hombre Sin estudios
## 4 18 Hombre Estudios Primarios
## 5 20 Mujer Estudios Superiores
## 6 30 Hombre Estudios SecundariosOtra librería que se puede utilizar para leer y guardar un fichero en formato .sav es la librería haven
library(haven)
misDatos2=read_sav("http://www.dma.ulpgc.es/profesores/personal/stat/cursoR4ULPGC/datos/datosPractica1.sav")Importación desde un archivo .dta de Stata
La librería foreign permite importar también archivos en el formato propio de Stata mediante la función read.dta():
library(foreign)
misDatosStata=read.dta("miArchivo.dta")Pueden consultarse las opciones disponibles para esta función mediante help(read.dta).
Importación desde un archivo .csv (Comma Separated Values)
En R utilizaremos read.csv(nombre_del_archivo.csv) para leer archivos csv en formato anglosajón y read.csv2(nombre_del_archivo.csv) para formato latino:
misDatos3=read.csv2("http://www.dma.ulpgc.es/profesores/personal/stat/cursoR4ULPGC/datos/datosPractica1.csv")str(misDatos3)## 'data.frame': 200 obs. of 3 variables:
## $ edad : int 28 41 30 36 25 40 28 38 25 31 ...
## $ sexo : int 0 1 1 0 0 0 1 0 1 0 ...
## $ estudios: int 0 1 2 1 2 2 0 3 1 0 ...head(misDatos3)## edad sexo estudios
## 1 28 0 0
## 2 41 1 1
## 3 30 1 2
## 4 36 0 1
## 5 25 0 2
## 6 40 0 2En caso de encontrarnos con archivos que tengan otras especificaciones en su codificación, podemos utilizar el comando read.table(). Por ejemplo, si en el archivo anterior el símbolo decimal fuera la coma y el separador entre valores fuera el tabulador en lugar del punto y coma, podríamos leerlo mediante:
misDatos4=read.table("nombre_del_fichero",sep="\t", dec=",")Importación desde un archivo .rdata creado en una sesión previa de R.
Para importar un archivo .rdata se utiliza la función load(). Debe tenerse en cuenta que esta función carga en memoria todos los data.frames guardados en dicho archivo, por lo que no es necesario asignar el resultado del load() a ningún objeto. Es conveniente además utilizar la opción verbose=TRUE para que R muestre el nombre de los objetos que se incluyen en el archivo que estamos leyendo:
Descargar el fichero Aquí
load("datos/miArchivoDeDatos.rdata", verbose=TRUE)
© 2016 Angelo Santana, Carmen N. Hernández, Departamento de Matemáticas ULPGC