Tarea 3: Riesgo Relativo y Odds Ratio
Para tratar de analizar las características y propiedades del riesgo relativo y odds-ratio, utilizaremos los resultados obtenidos por los autores del siguiente artículo, disponible a través de PubMed sin ningún tipo de restricción:

Los autores describen el método seguido para la recogida de datos:

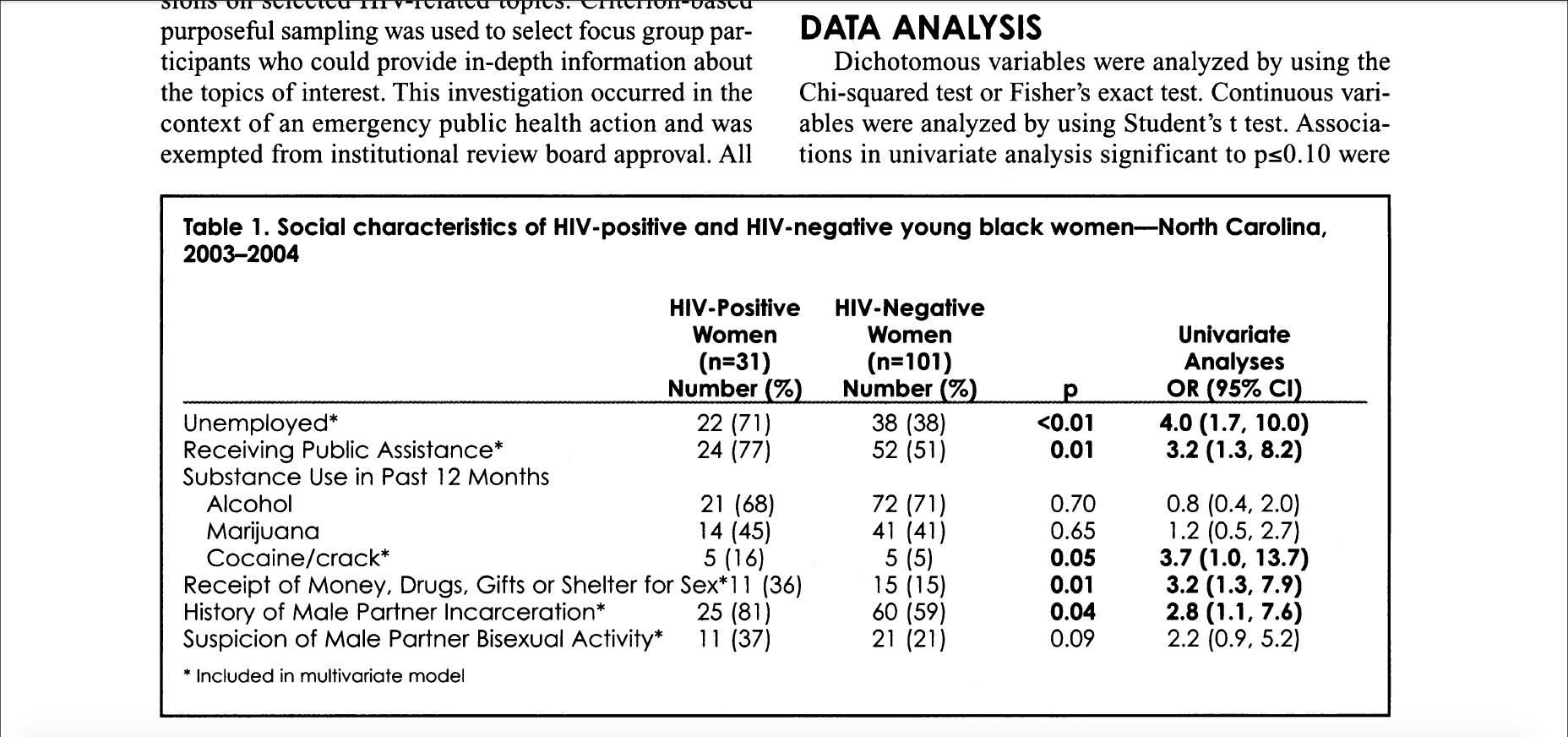
y resumen las características sociales del estudio de casos-controles de mujeres negras jóvenes, con o sin HIV, a través de la siguiente tabla:
En el fichero HIV.csv se incluyen los datos de las variables que parecen ser significativas según el estudio realizado por los autores del artículo: Desempleo; recepción de asistencia pública; uso de cocaina/crack; recepción de dinero, drogas,… a cambio de sexo; encarcelamiento de la pareja. Con estos datos, trataremos de analizar el riesgo relativo (RR) y odds-ratio (OR) de padecer HIV según estén presentes o no las distintas características sociales/factores de riesgo mencionados.
Riesgo Relativo
Comenzaremos con el riesgo relativo (RR). Para ello tengamos en cuenta que el RR de HIV para el factor T se define como:
\[ RR=\frac{P\left(HIV+\left|T+\right.\right)}{P\left(HIV+\left|T-\right.\right)} \]
donde \(HIV+\) significa que el sujeto padece la enfermedad, \(T+\) significa que el posible factor de riesgo está presente y \(T-\) que está ausente.
Utilizaremos Jamovi para facilitar el análisis que vamos a realizar. En primer lugar, cargamos los datos del fichero HIV.csv:
Factor de riesgo “Desempleo”
Centrando nuestra atención en el desempleo como factor de riesgo, construimos una tabla de doble entrada con las variables HIV y Unemployed que nos permitirá calcular el riesgo relativo de padecer HIV para el factor de riesgo Unemployed. Para ello, en la pestaña Analyses elegimos el menú Frequencies y en el apartado Contingency Tables ubicamos la variable HIV por columnas y la otra por filas. Además, en la barra Statistics desmarcamos todas las opciones:
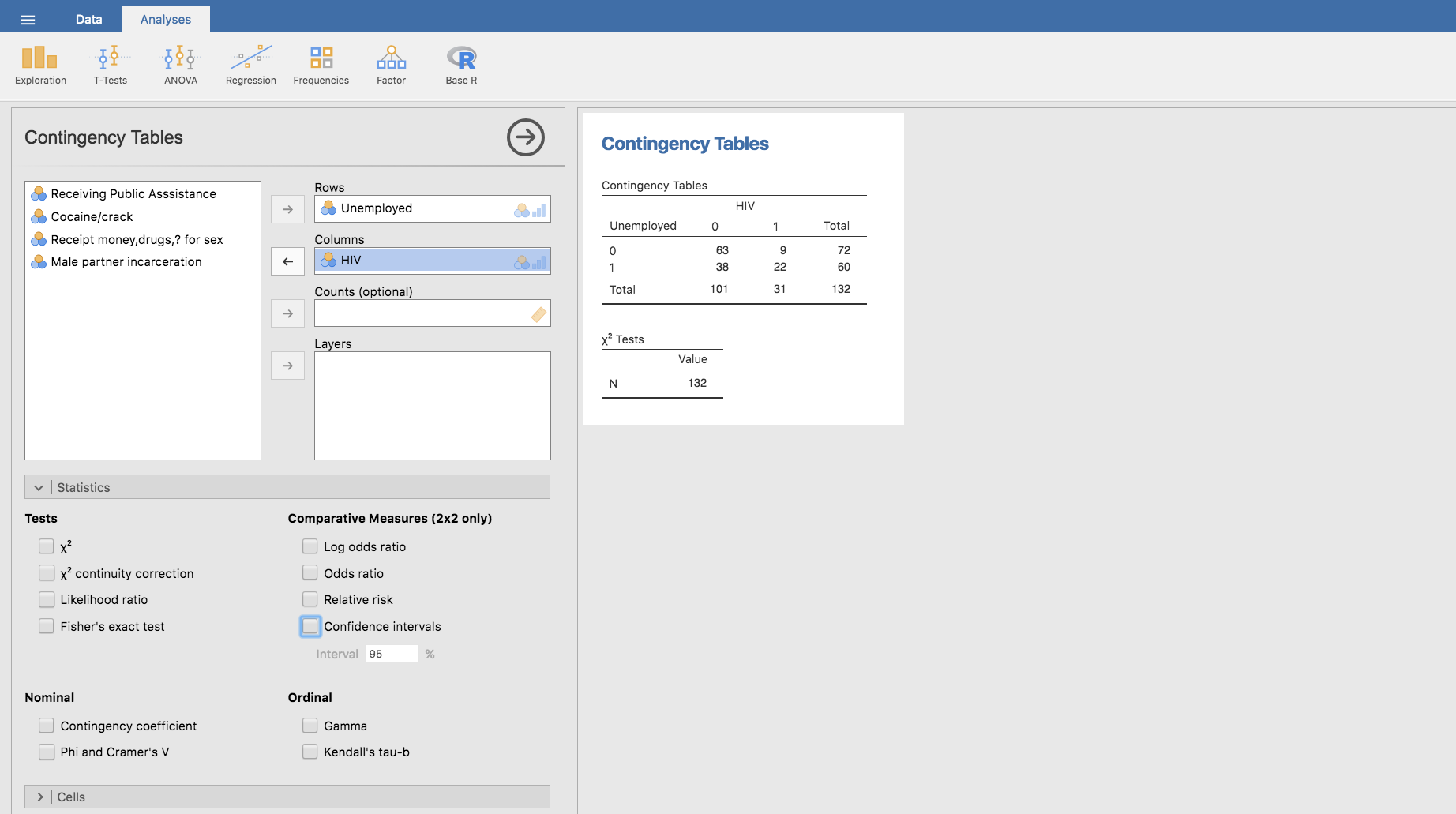
La tabla nos muestra cuántas mujeres con HIV están desempleadas, cuántas sin HIV tampoco tienen empleo, etc. Para mejorar la interpretación de la tabla, haremos lo siguiente:
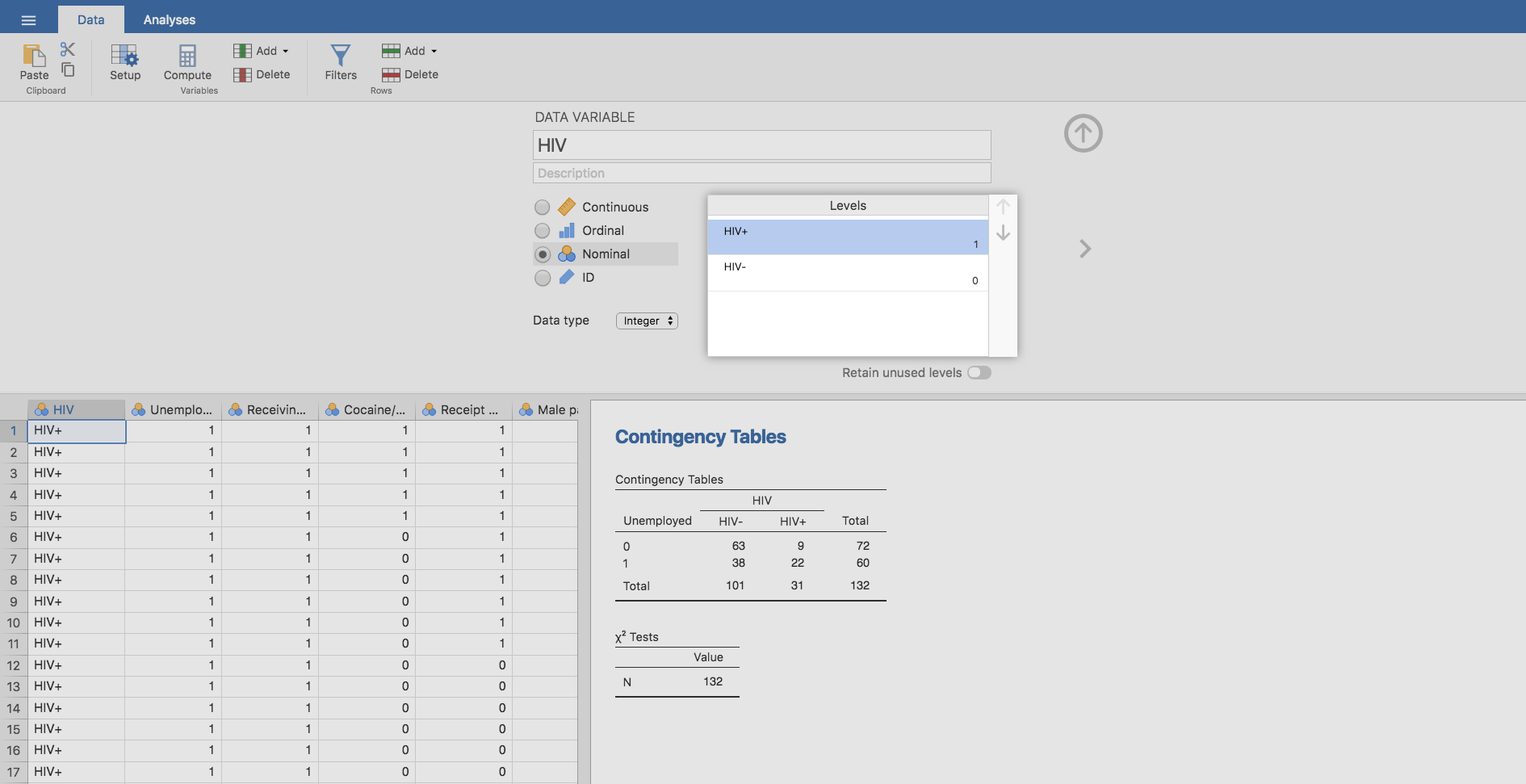
- En la variable HIV: Sustituimos los unos por HIV+ (sí tiene la enfermedad) y los ceros por HIV- (no la tiene). Para ello, en la pestaña Data hacemos doble clic en HIV y en la ventana emergente, en Levels, realizamos los cambios mencionados:
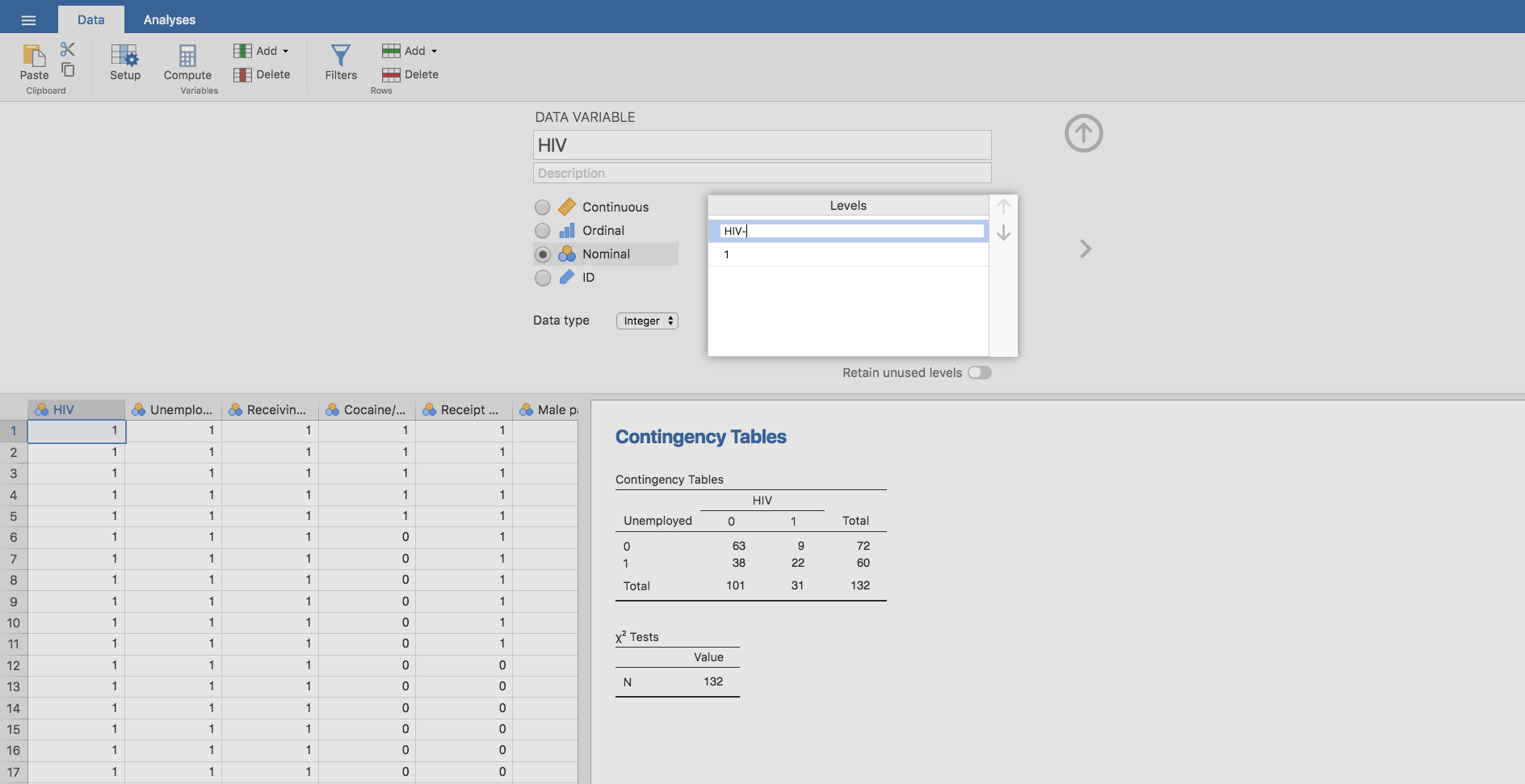
Además, ordenamos los niveles de la variable, situando HIV+ en primer lugar mediante la flecha que aparece en la esquina superior derecha de la ventana Levels:
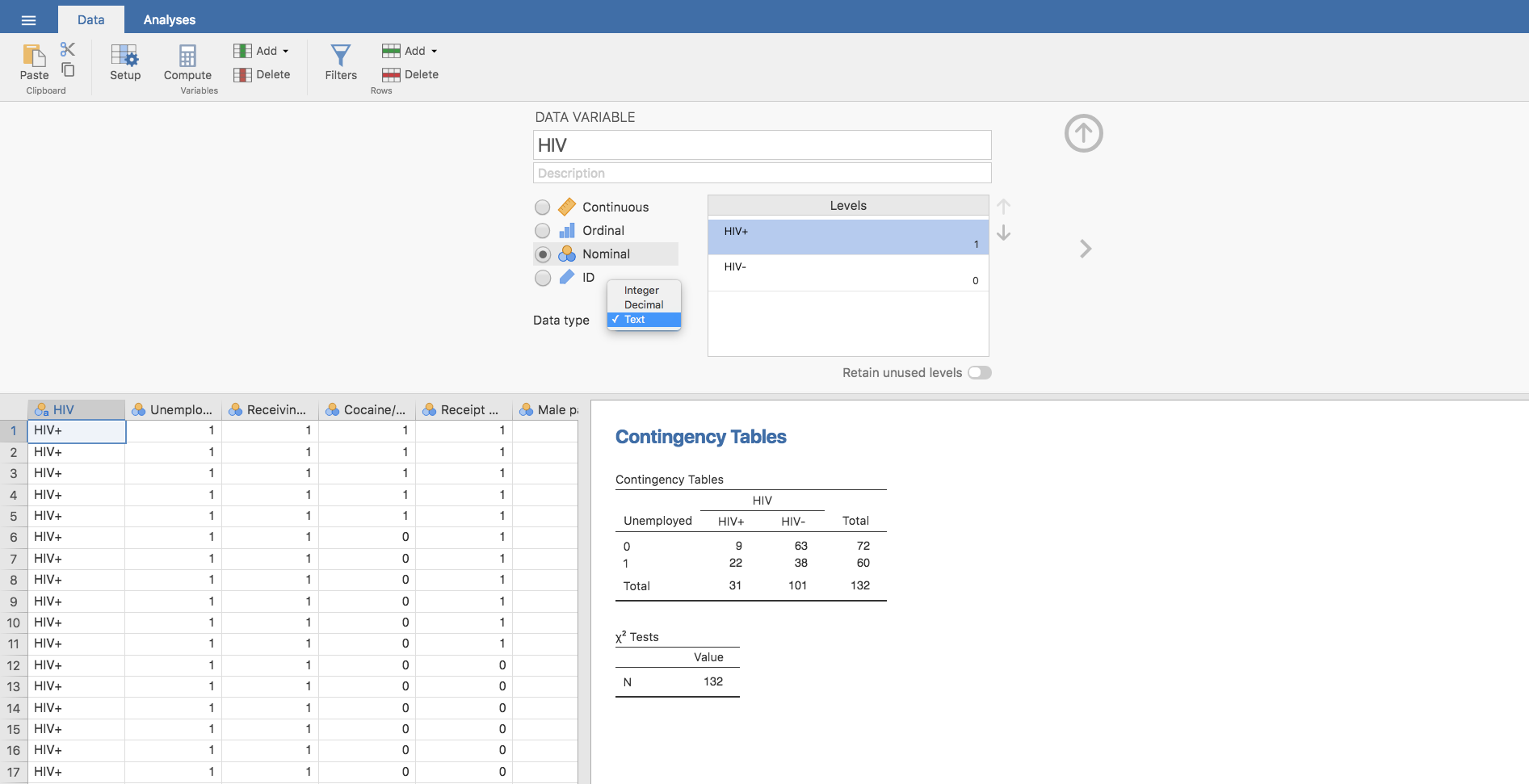
Finalmente, en Data type elegimos la opción Text:
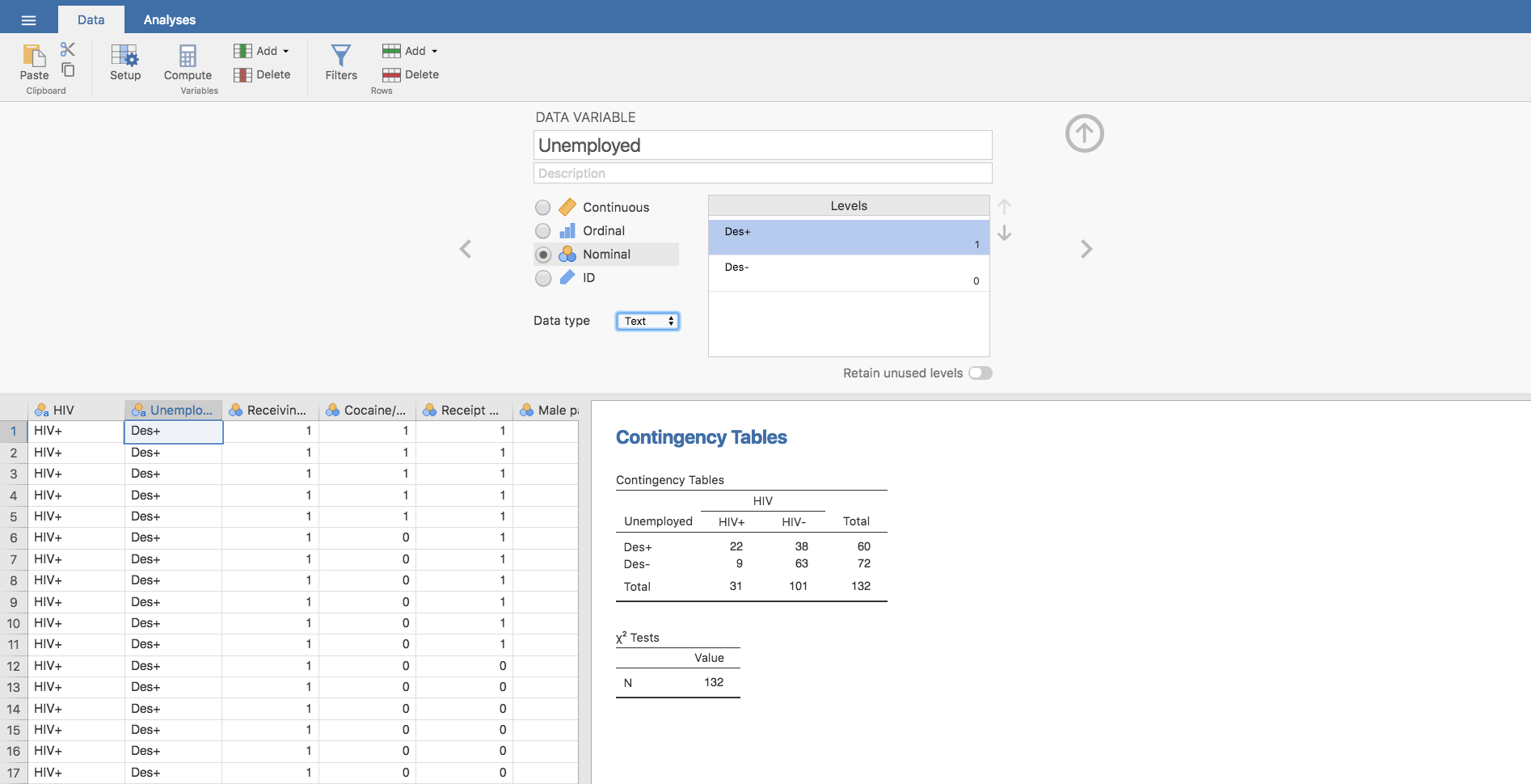
- Con la variable Unemployed seguimos los mismos pasos que con la anterior: sustituyendo los unos por Des+ (está desempleada) y los ceros por Des- (tiene empleo).
Una vez realizados estos cambios, el aspecto de la tabla de contingencia será el siguiente:
A continuación nos centramos en el cálculo de las frecuencias relativas por columnas en la tabla de doble entrada. Para ello, basta con volver a la pestaña Analyses, hacer doble clic en la tabla mostrada por Jamovi, y en la barra Cells elegimos Column en el apartado Percentages:
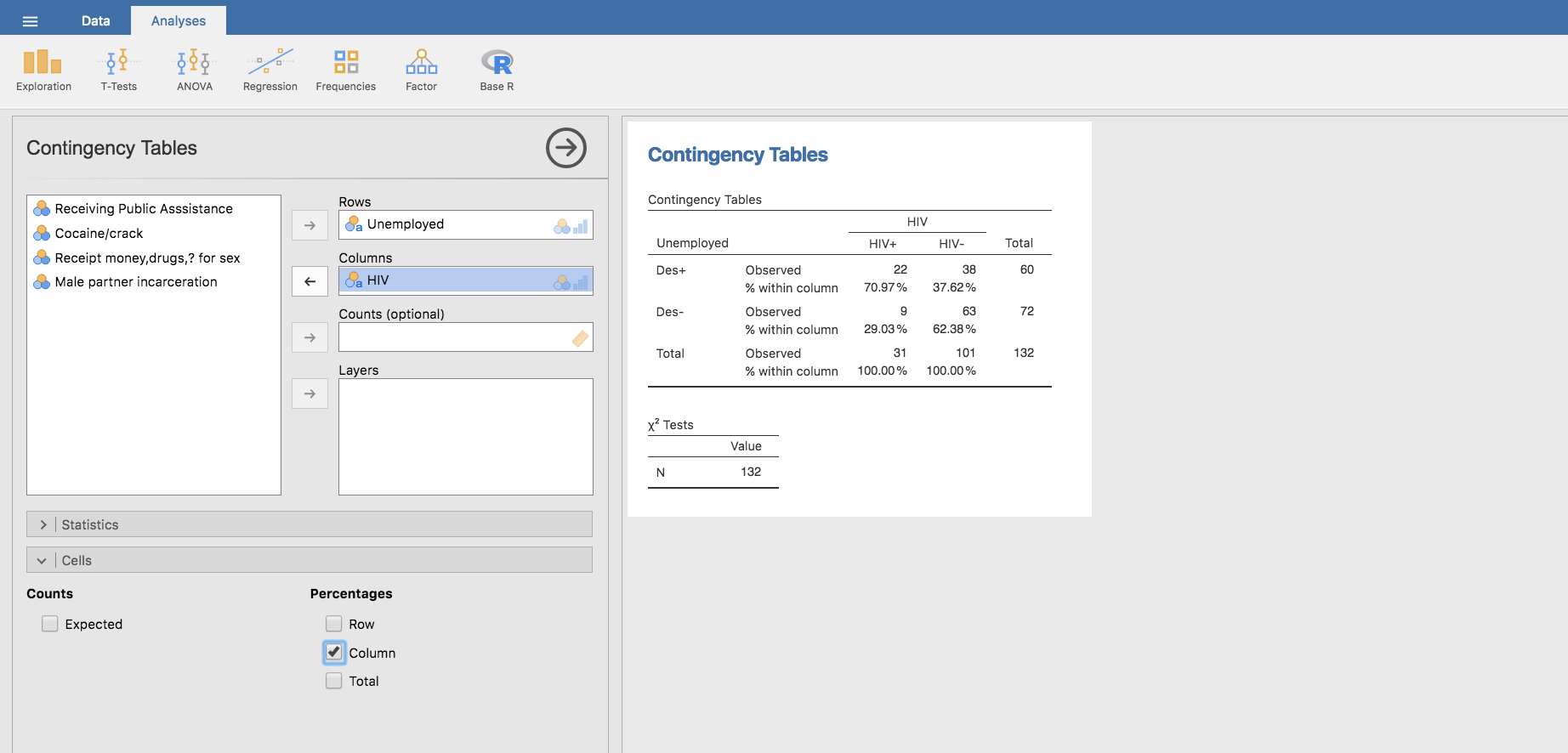
Automáticamente, se añaden nuevas filas con los porcentajes por columnas en la tabla existente. Estos porcentajes confirman que, efectivamente, el 71% de las mujeres con HIV estaban desempleadas, y también estaban desempleadas el 38% de las que no padecen HIV, tal como figura en la tabla que los autores incluyen en el artículo.
Para calcular el riesgo relativo utilizando la tabla de doble entrada, necesitamos la probabilidad \(P\left(HIV+\left|Des+\right.\right)\), es decir, la probabilidad de padecer HIV cuando se está en desempleo, y \(P\left(HIV+\left|Des-\right.\right)\), la probabilidad de padecer HIV cuando NO se está en desempleo. Por tanto, necesitamos las probabilidades por filas de nuestra tabla, que se obtienen igual que antes con solo hacer clic en Row:
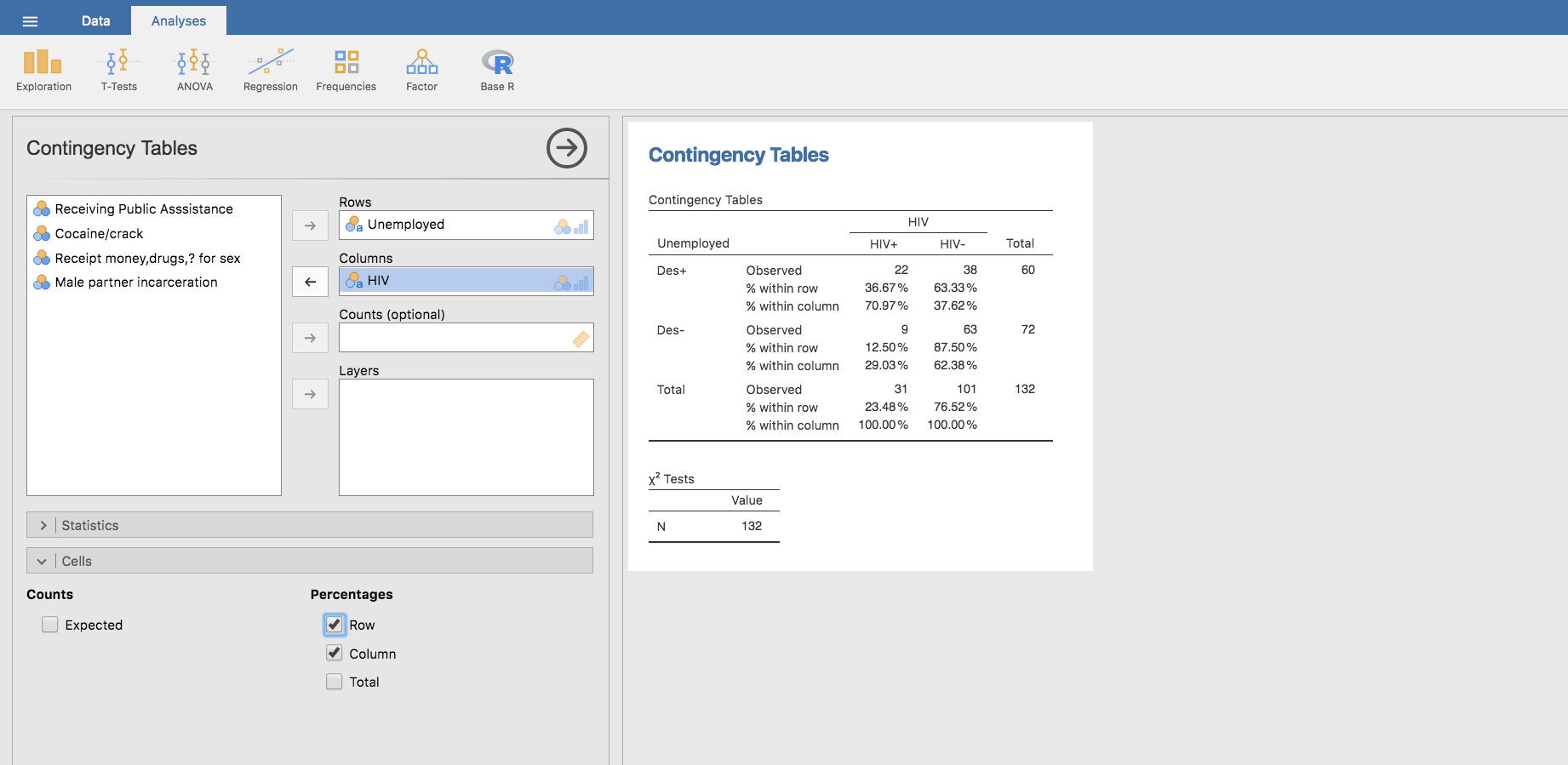
Una vez tenemos las frecuencias relativas por filas, obtenemos el riesgo relativo de padecer HIV para el factor de riesgo Unemployed, tomando las frecuencias relativas por filas que aparecen en la columna de HIV+ y dividiendo la primera entre la segunda:
\[ RR=\frac{P\left(HIV+\left|Des+\right.\right)}{P\left(HIV+\left|Des-\right.\right)} = \frac{0.3667}{0.125}=2.9336\]
Es decir, el riesgo relativo se calcula a partir de las frecuencias relativas por filas que proporciona la tabla de doble entrada. Pero también puede obtenerse directamente con Jamovi, sin más que expandir la barra Statistics y hacer clic en Relative risk en el apartado Comparative Measures (2x2 only):
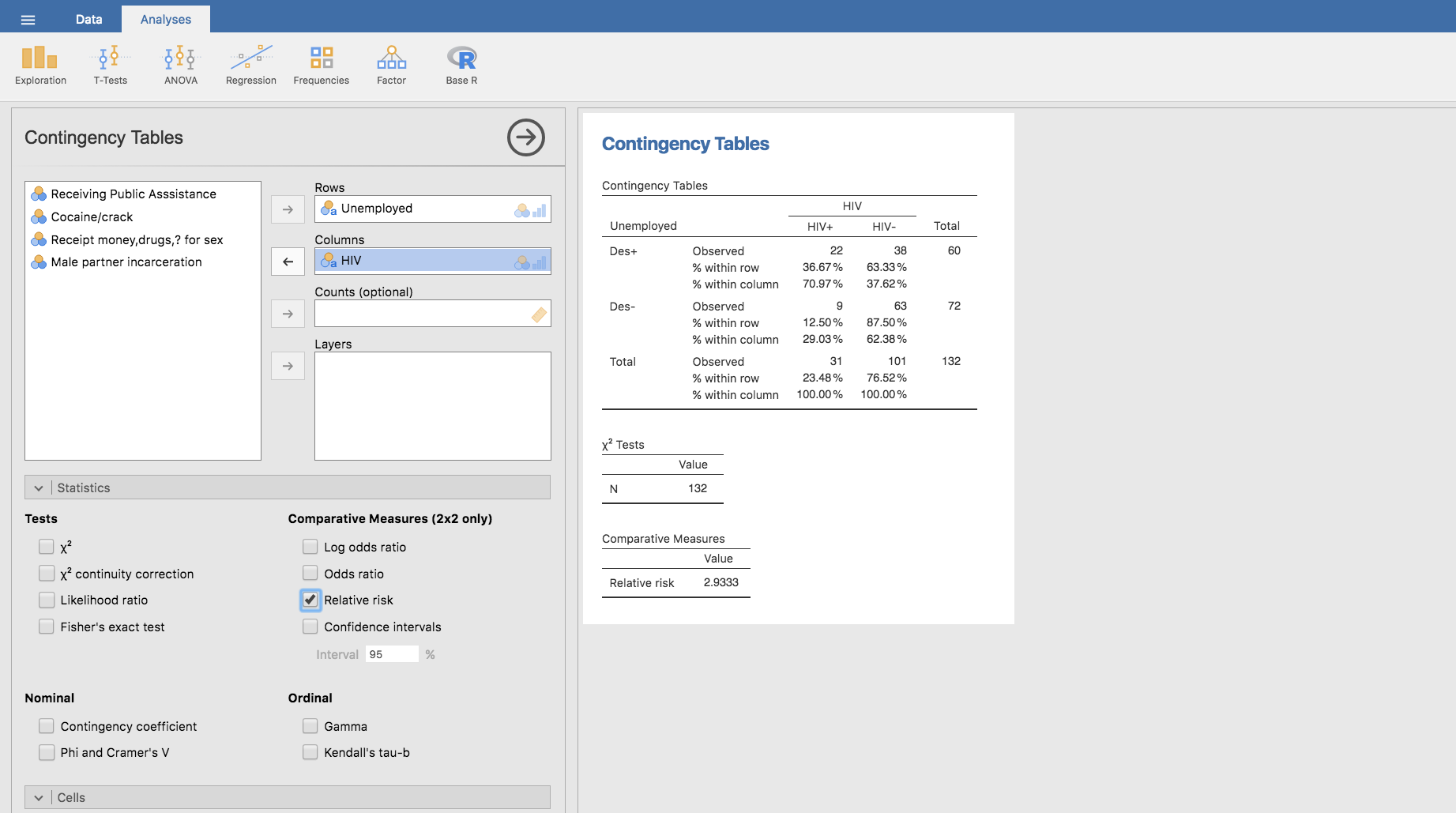
Como conclusión, nuestro análisis del desempleo como factor de riesgo para el HIV, indica que el riesgo de padecer HIV es casi el triple entre las mujeres negras desempleadas que entre las que tienen empleo.
¿Es correcto calcular el Riesgo Relativo en este contexto (estudio caso-control)?
Para responder a esta pregunta observemos lo siguiente: en un estudio de casos y controles es el investigador el que decide cuántos casos y cuántos controles se seleccionan. Supongamos que hubiésemos tenido la posibilidad de tomar 310 casos (mujeres con HIV) en lugar de los 31 que tenemos, y 303 controles (en lugar de los 101 que tenemos). En otras palabras, multiplicamos por 10 el tamaño de la muestra de casos y por 3 el tamaño de la muestra de controles. Supongamos además que las proporciones de mujeres empleadas y desempleadas siguen siendo las mismas en ambos grupos. En tal caso, los datos disponibles serían:
| HIV+ | HIV- | |
|---|---|---|
| Des+ | 220 | 114 |
| Des- | 90 | 189 |
Podemos comprobar que las proporciones por columnas coinciden con las mostradas en la tabla anterior:
| HIV+ | HIV- | |
|---|---|---|
| Des+ | 0.71 | 0.38 |
| Des- | 0.29 | 0.62 |
Pero ahora las proporciones por filas son distintas:
| HIV+ | HIV- | |
|---|---|---|
| Des+ | 0.6587 | 0.3413 |
| Des- | 0.3226 | 0.6774 |
y, consecuentemente, también lo es el riesgo relativo:
\[ RR=\frac{P\left(HIV+\left|Des+\right.\right)}{P\left(HIV+\left|Des-\right.\right)} = \frac{0.6587}{0.3226}=2.0418\]
que ha disminuído a \(2.04\). Es decir, el riesgo relativo ha disminuido en una tercera parte (de casi 3 a casi 2) simplemente por haber cambiado el número de casos y controles elegidos, aún cuando las prevalencias del factor de riesgo no han cambiado en cada grupo.
Así pues, en los estudios de casos y controles, el riesgo relativo depende de los tamaños de muestra elegidos arbitrariamente por el investigador, y no es por tanto una característica intrínseca de la asociación entre la enfermedad y el factor de riesgo. Consecuentemente, el riesgo relativo no puede ser un indicador útil del valor de dicha asociación, y no puede usarse con el objetivo de medir dicho valor.
Es responsabilidad del investigador tener en cuenta que el RR en este problema (diseño caso-control), carece de sentido.
¿Es el riesgo relativo realmente una medida de asociación?
Señalemos además que el riesgo relativo no es propiamente una medida de asociación en sentido estricto. De una medida de asociación se espera que la asociación entre A y B sea la misma que entre B y A, lo que no ocurre con el riesgo relativo. Podemos comprobar esta afirmación de manera muy simple: hemos visto que en el estudio original, el riesgo relativo de padecer HIV (digamos A) según que la mujer esté o no desempleada (digamos B) es 2.9333; para calcular ahora el riesgo de que una mujer esté desempleada (B) según que tenga o no HIV (A), deberíamos partir de la tabla traspuesta de la original. Para obtenerla, basta con intercambiar las variables en nuestro análisis anterior: situamos la variable HIV por filas (en Rows) y Unemployed por columnas (en Columns), y automáticamente se actualizan todos los valores calculados anteriormente:
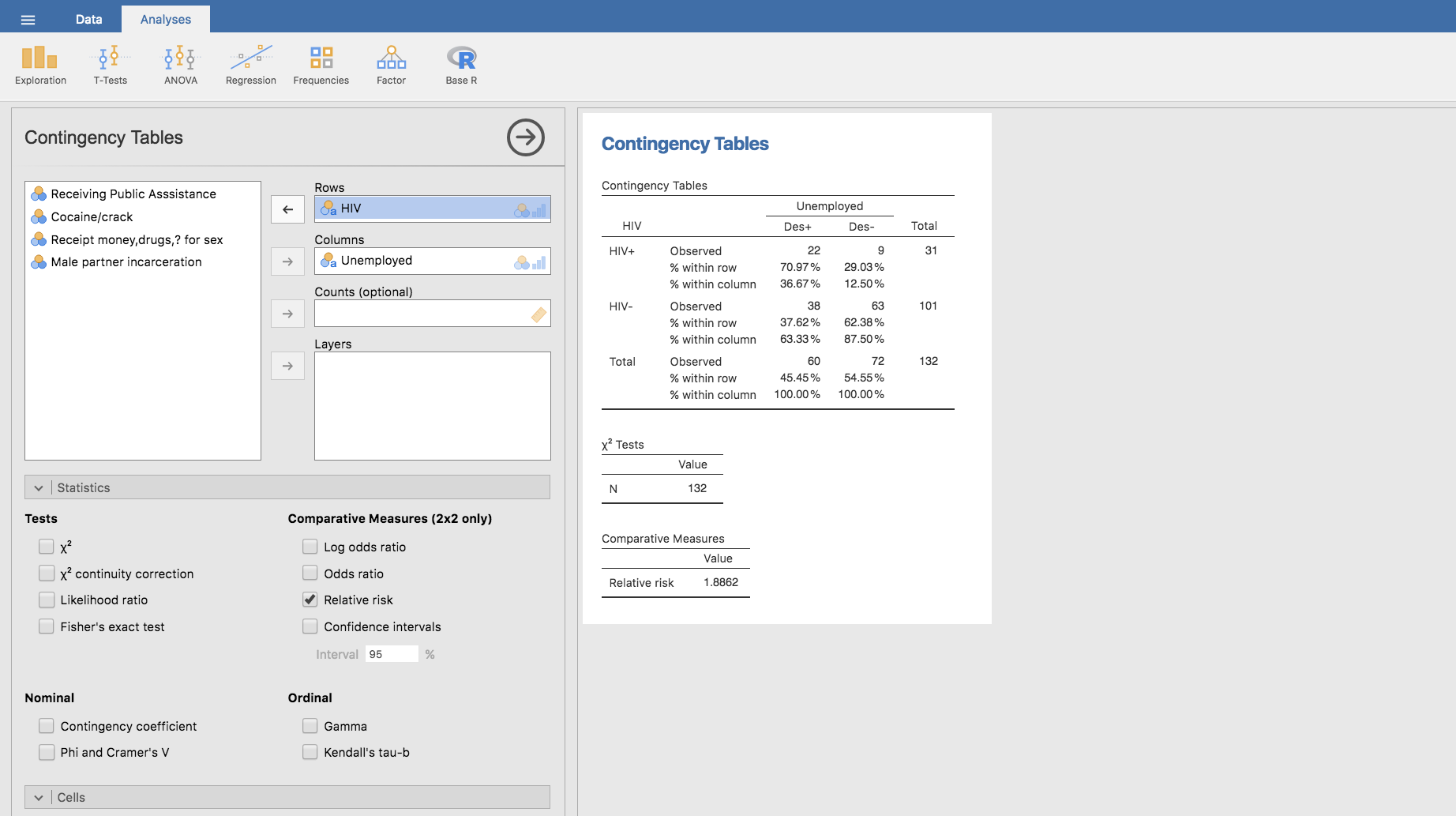
Repitiendo el procedimiento seguido con la tabla anterior, podemos calcular el riesgo relativo utilizando las frecuencias relativas por filas o directamente haciendo clic en Relative risk. En ambos casos, se obtiene que el riesgo de desempleo según se padezca o no HIV es \(1.8862\).
Observamos que este riesgo relativo no coincide con el calculado anteriormente: el riesgo de HIV condicionado por el desempleo (asociación de A con B) no coindice con el riesgo de desempleo condicionado por el HIV (asociación de B con A), lo que confirma que el riesgo relativo no es simétrico.
Odds ratio
La odds-ratio que mide la asociación entre dos eventos A y B se define como:
\[OR\left(A,B\right)=\frac{P({A}\;|\;{B})/P({{A}^{c}}\;|\;{B})}{P({A}\;|\;{{B}^{c}})/P({{A}^{c}}\;|\;{{B}^{c}})}\]
Puede comprobarse que la odds-ratio sí que es una medida simétrica y que:
\[OR\left(A,B\right)=OR\left(B,A\right)=\frac{P({B}\;|\;{A})/P({{B}^{c}}\;|\;{A})}{P({B}\;|\;{{A}^{c}})/P({{B}^{c}}\;|\;{{A}^{c}})}\]
A modo de ejemplo, si volvemos a la relación entre HIV y desempleo del ejemplo anterior, si consideramos que el suceso \(A\) es el HIV+, entonces el contrario \(A^c\) es el HIV-. Asimismo, si el suceso \(B\) es estar desempleada (\(Des+\)), el \(B^c\) sería tener empleo (\(Des-\)). Entonces, podríamos calcular la OR mediante:
\[OR\left(HIV,Des\right)= \frac{P({HIV+}\;|\;{Des+})/P({HIV-}\;|\;{Des+})}{P({HIV+}\;|\;{Des-})/P({HIV-}\;|\;{Des-})}\]
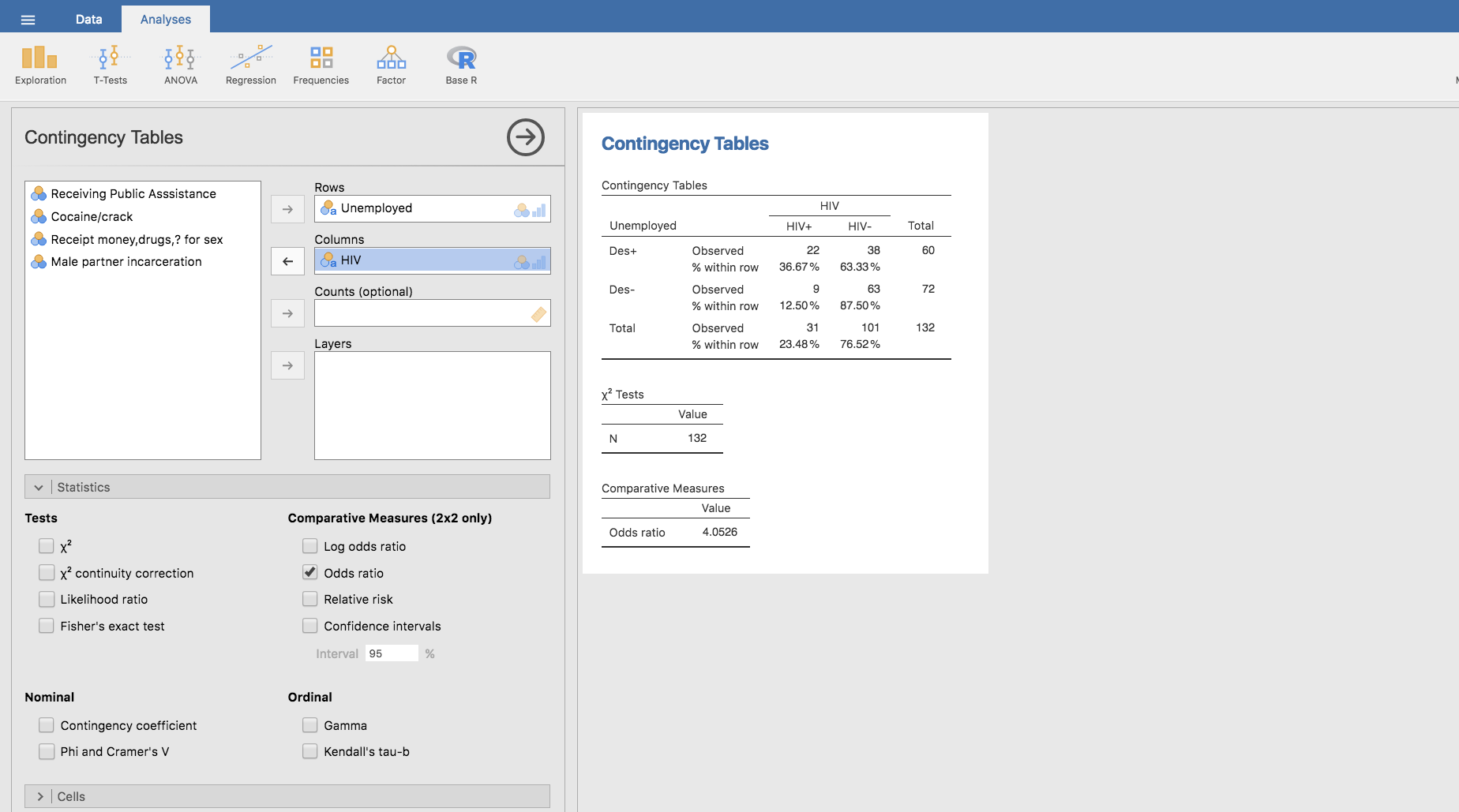
Para obtener este valor de OR partimos nuevamente de la primera tabla utilizada en la sección anterior, y de sus proporciones por filas:
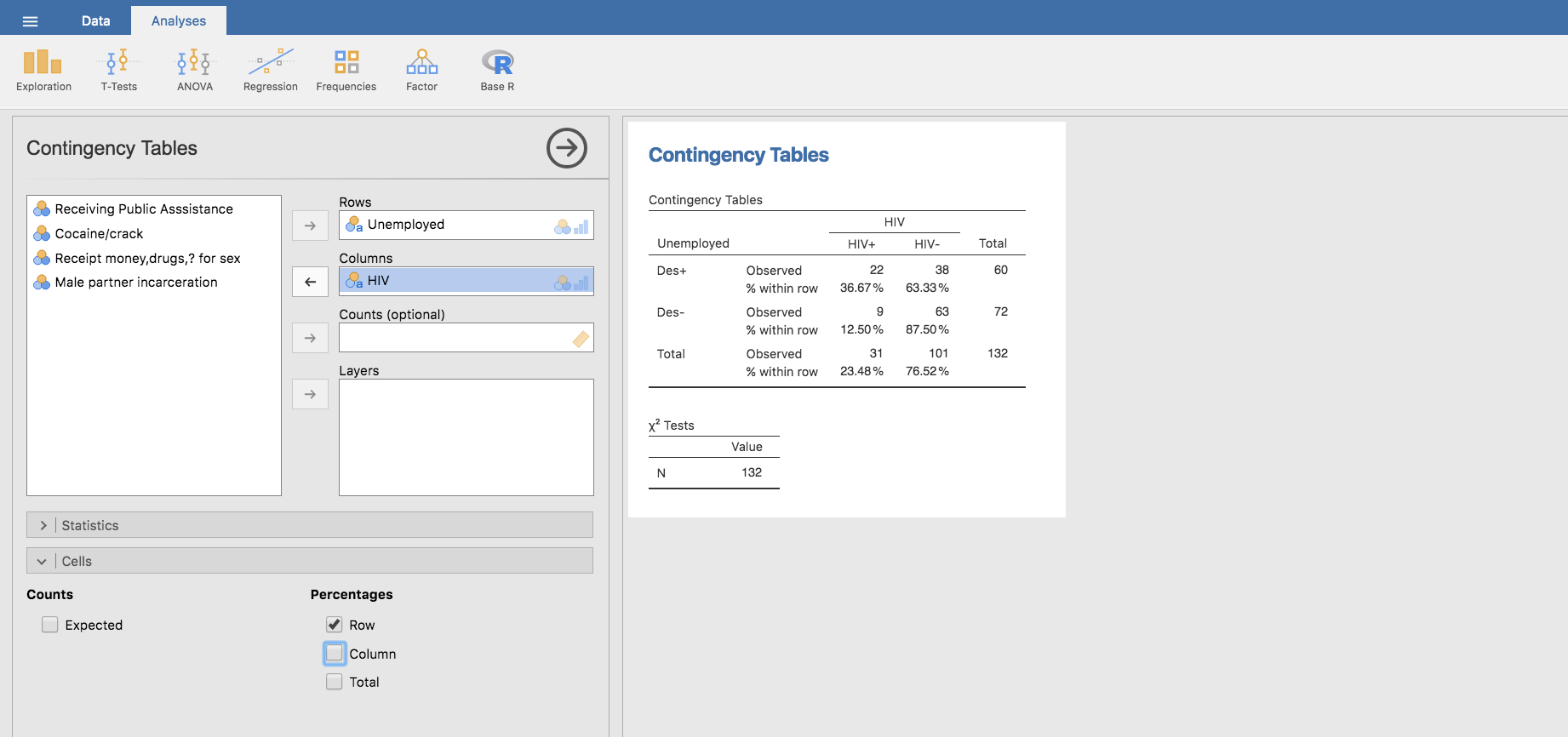
Tenemos entonces:
\[OR = \frac{0.3667 / 0.6333}{0.125 / 0.875}=4.0532\]
que en Jamovi se obtiene a través de la barra Statistics, haciendo clic en Odds ratio:
Por otra parte, si queremos calcular:
\[OR\left(Des,HIV\right)= \frac{P({Des+}\;|\;{HIV+})/P({Des-}\;|\;{HIV+})}{P({Des+}\;|\;{HIV-})/P({Des-}\;|\;{HIV-})}\]
volvemos a partir de la tabla original:
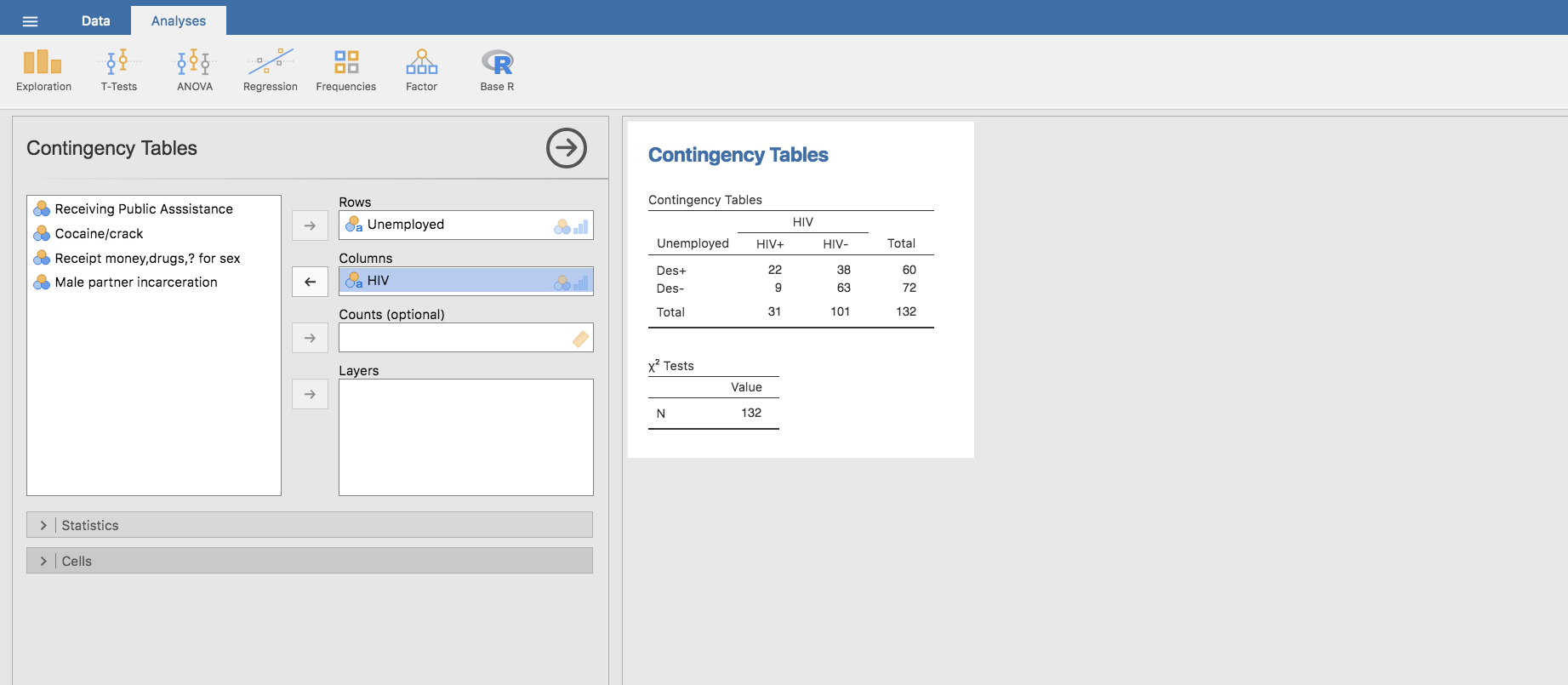
pero ahora habremos de calcular las proporciones por columnas:
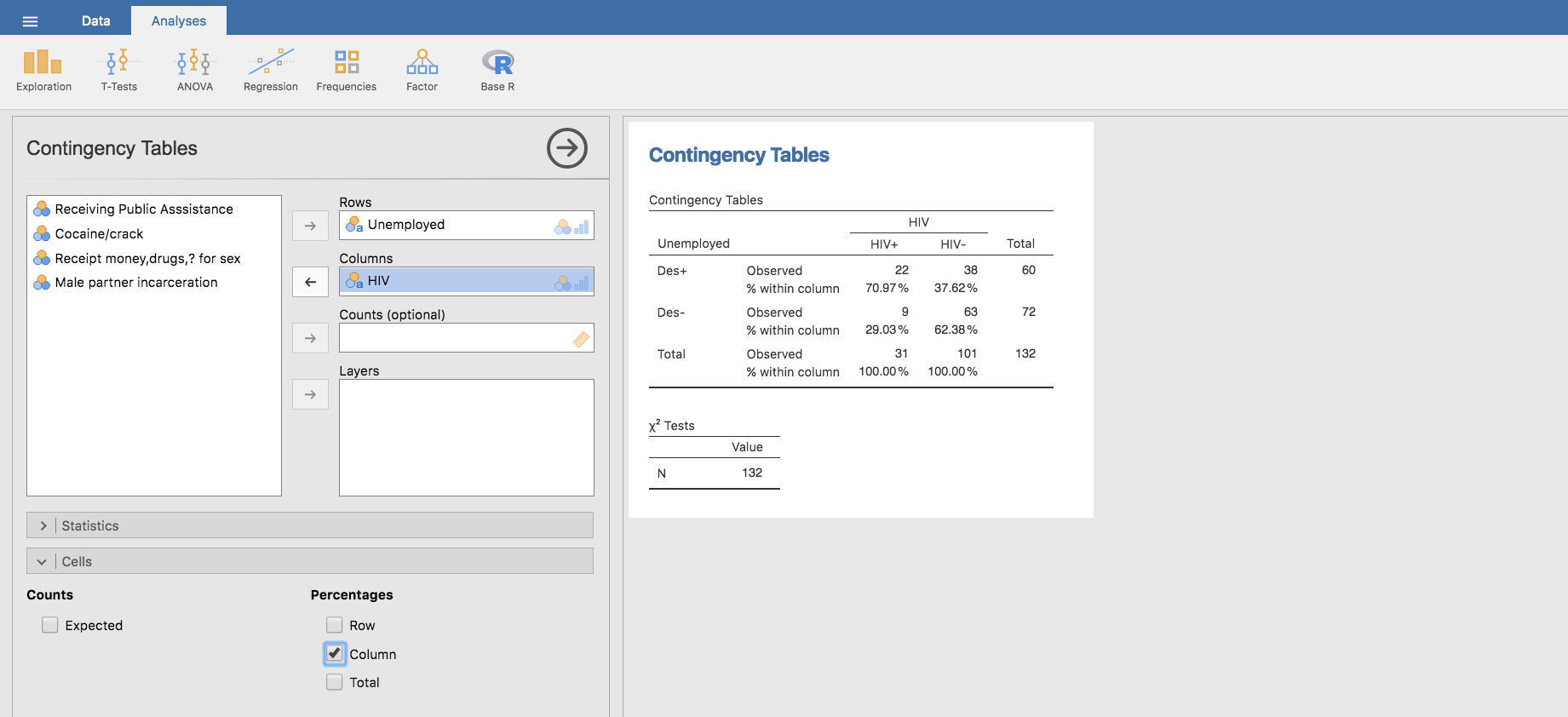
Tenemos entonces que la odss ratio se obtiene como:
\[OR = \frac{0.7097 / 0.2903}{0.3762 / 0.6238}=4.0537\]
o directamente con Jamovi, haciendo clic en Odds ratio:
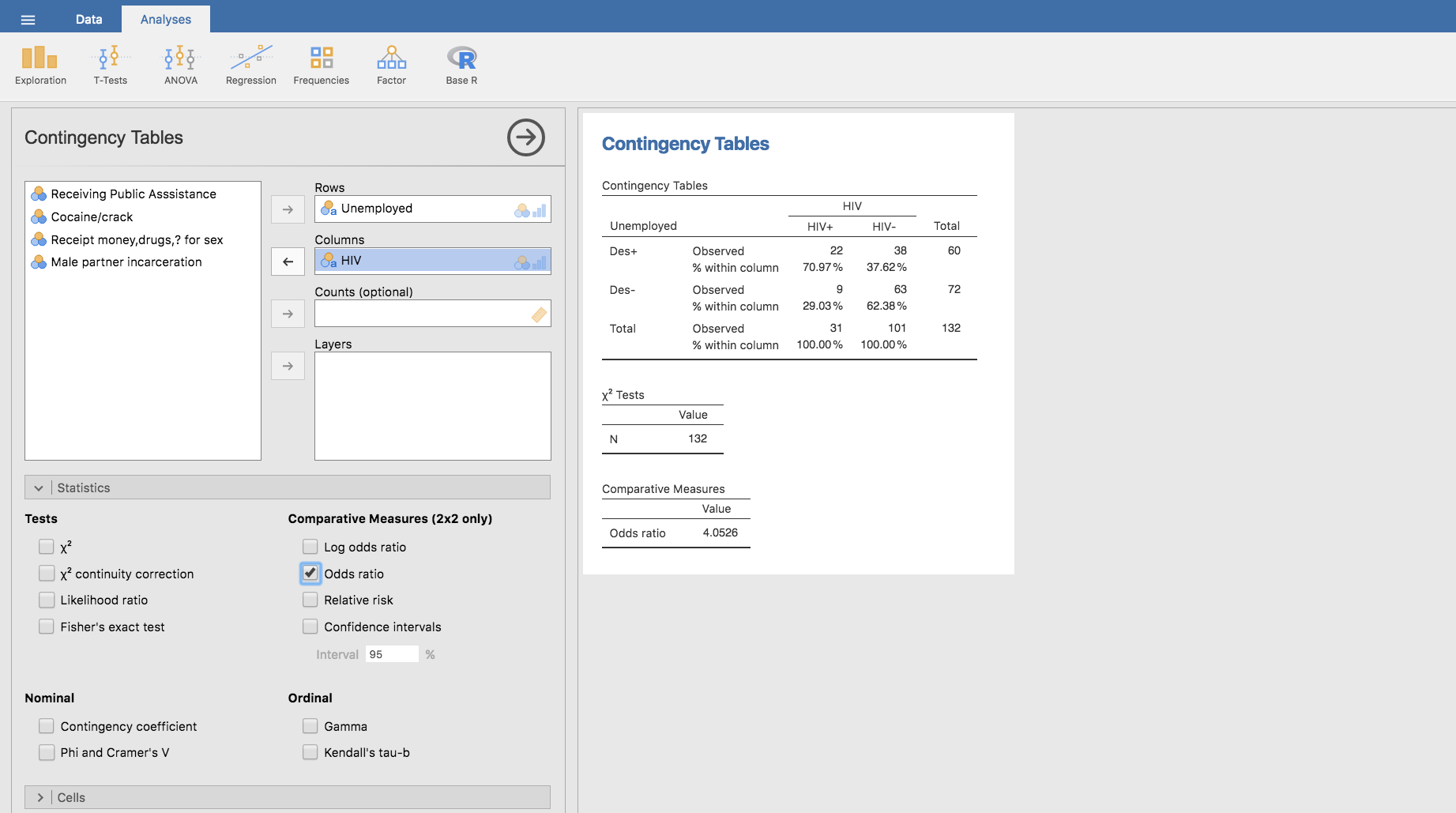
Se aprecia un error de \(0.0005\) entre los valores de la OR calculados directamente sobre las tablas de contingencia, así como una diferencia de milésimas entre la OR calculada sobre la tabla y la calculada por Jamovi. Estas diferencias son consecuencia de los redondeos aplicados por Jamovi al calcular las proporciones por filas y columnas. Por tanto, podemos obviarlas, y afirmar que este ejemplo confirma la simetría de la odds-ratio:
\[OR\left(HIV,Des\right) = OR\left(Des,HIV\right) \]
Para finalizar, comprobamos que la odds-ratio puede obtenerse también a partir de la tabla cruzada de frecuencias absolutas:
| B+ | B- | |
|---|---|---|
| A+ | n[1,1] | n[1,2] |
| A- | n[2,1] | n[2,2] |
sin necesidad de calcular proporciones por filas ni por columnas, mediante:
\[OR = \frac{n[1,1]\cdot n[2,2]}{n[1,2]\cdot n[2,1]}\]
En este caso, hay que señalar que el cálculo es correcto si, y solo si, en la tabla cruzada la categoría positiva es la primera tanto en filas como en columnas.
Si calculamos la OR de esta manera en la tabla inicial, que está configurada tal y como acabamos de especificar en el párrafo anterior:
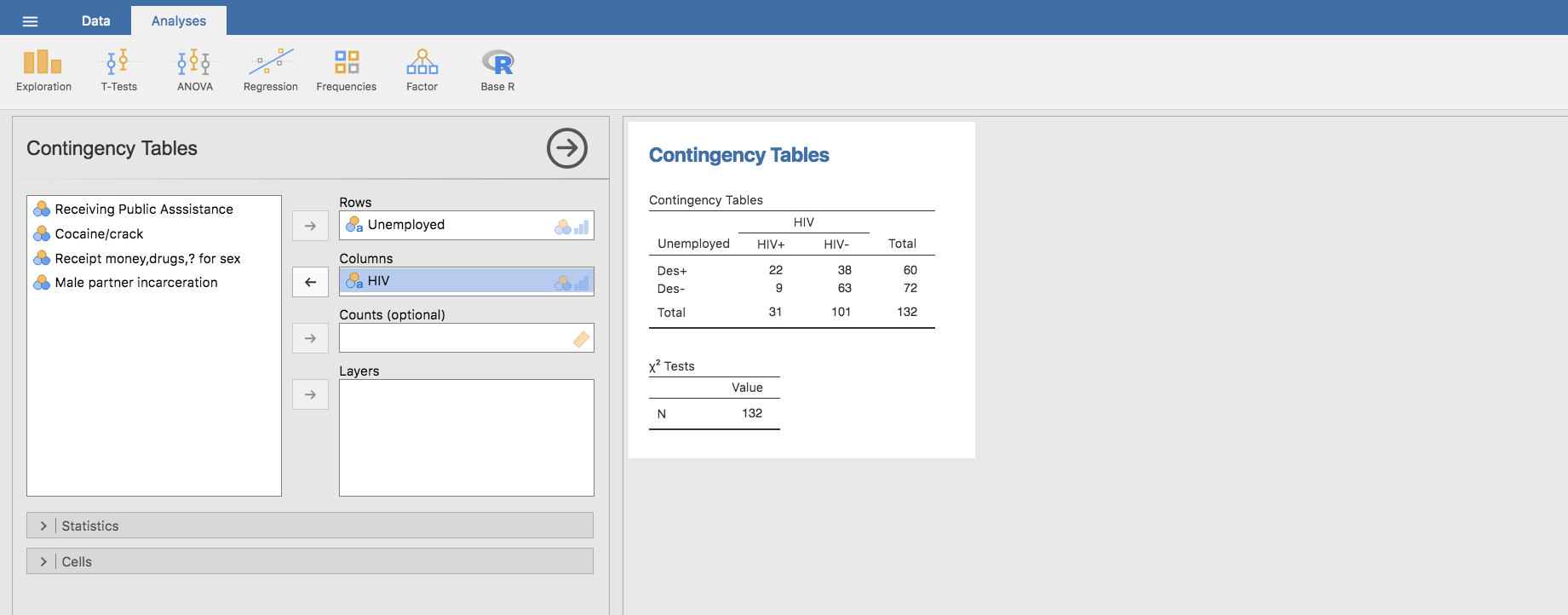
volvemos a obtener el mismo resultado:
\[OR = \frac{n[1,1]\cdot n[2,2]}{n[1,2]\cdot n[2,1]}=\frac{22\cdot 63}{38\cdot 9}=4.0526\]
Ejercicios
Calcular las odds-ratio para los restantes factores de riesgo considerados en el estudio original del HIV en mujeres negras (Recibir ayudas sociales, consumir cocaína/crack, prostitución o encarcelamiento de la pareja)
Utilizando la base de datos de Telde:
2.1. Calcular la odds-ratio entre diabetes e hipertensión.
2.2. Calcular la odds-ratio entre las variables tabaco y alcohol.
Utilizando la base de datos de Telde, construye la variable IMC del siguiente modo: \[ IMC=\frac{Peso}{\big (\frac{Talla}{100}\big )^2}\] y construye la variable OBESIDAD con los valores OB+ para los sujetos con \(IMC>30\) y OB- cuando el IMC es menor o igual que \(30\) (definir la nueva variable con el condicional IF(IMC>30,“OB+”,“OB-”)).
3.1. Calcular la OR entre obesidad y sedentarismo.
3.2. Calcular la OR entre obesidad y DM.